이번 포스팅은 다음의 논문을 스터디하여 정리하였다:
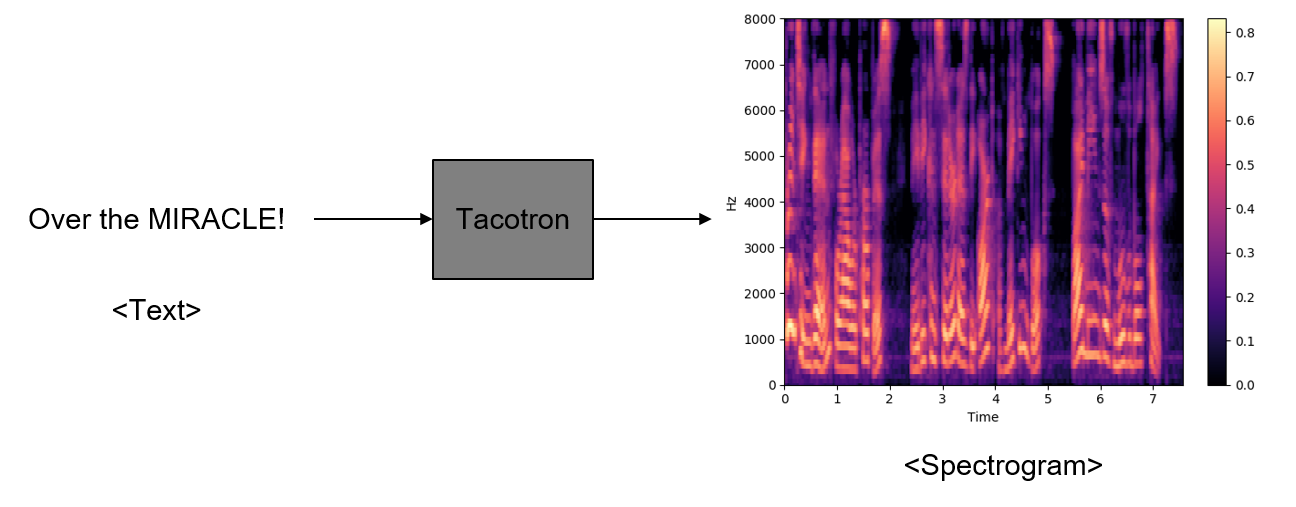
Tacotron?
2018년 구글에서 새로운 TTS 모델인 Tacotron 2를 발표하였다. 구글이 자신들의 블로그에서 주장하기를 거의 사람이 직접 내는 음성과 비슷한 퀄리티의 음성을 생성할 수 있는 모델이라고 홍보하고 있는데 실제로 Tacotron 2가 생성한 음성 샘플을 들어보면 사람의 목소리인지 구분하기 힘들 정도다. Tacotron 2의 음성 샘플은 링크를 통해서 들어볼 수 있다.
Tacotron 2에 앞서서 먼저 발표된 모델이 2017년에 발표된 Tacotron이다. 저자들은 Tacotron은 이전 TTS 모델들과 비교해서 다음과 같은 장점이 있다고 주장하고 있다.
- 텍스트를 입력으로 받아서 Raw Spectrogram을 바로 생성할 수 있음
- 간단하게 <text, audio> 페어를 이용하여 End-to-End로 학습이 가능함
특히 이러한 End-to-End로 학습할 수 있다는 점은 여러 측면에서 좋은 장점을 가질 수 있다. 먼저 End-to-End가 아닌 경우에는 다음과 같은 문제점이 있을 수 있다.
- 방대한 Domain 전문 지식, 여기서는 음성에 대한 전문 지식들이 필요하다.
- 디자인에 어려움이 있을 수 있다.
- 트레이닝이 파이프라인 별로 따로 되면서 에러가 누적될 수 있고 복잡하다.
결과적으로 End-to-End로 학습하는 경우의 장점은 다음과 같이 정리할 수 있다.
- <text, audio> 페어로만 가지고 학습이 가능하다.
- Feature Engineering이 간단하다. 즉, 어떤 Feature를 뽑아서 넘겨주고 해야할지에 대한 디자인이 간단하다.
- 발화자, 언어, 감정 등의 Feature 등을 손쉽게 조절이 가능하다.
- 새로운 데이터에 더 Adaptable하다.
- 노이즈에 더 강하다.
위와 같은 주장들이 타당성이 있는 이유를 살펴보기 위해서는 기존 모델들의 특징을 한 번 살펴볼 필요가 있다.
기존의 TTS 모델
WaveNet (2016):
- 매우 강력한 오디오 생성 모델이다. 성능이 매우 좋아서 Tacotron의 Vocoder로 사용된다.
- 샘플 수준의 Autoregressive Model이라는 이유로 너무 느리다는 단점이 있다.
- TTS로 바로 활용할 수 없으며 TTS-Frontend로부터 Linguistic Feature를 입력으로 넣어줘야 하는 단점이 있다.
DeepVoice (2017):
- 각각의 TTS 파이프라인을 뉴럴넷 모델로 대체하였다.
- 학습이 End-to-End로 되지 않는다는 단점이 있다.
또한 최근에는 기계 번역에서 사용되었던 Encoder-Decoder 모델을 이용하여 음성 합성을 시도하는 연구들이 있었다. 2016년에 나온 모델에서는 Attention Mechanism을 이용하고 있으나 미리 학습된 HMM 모델이 Attention Mechanism으로 존재해야 하며 출력이 Audio 자체가 아닌 Vocoder 파라미터를 예측하는 방식이다. 따라서 Vocoder의 성능에 따라 결과가 달라지게 된다.
또한 최근의 Char2Wav 모델은 End-to-End로 학습하게 하였으나 여전히 Vocoder 파라미터를 예측하는 모델이라는 한계점이 있었다.
Encoder-Decoder 모델
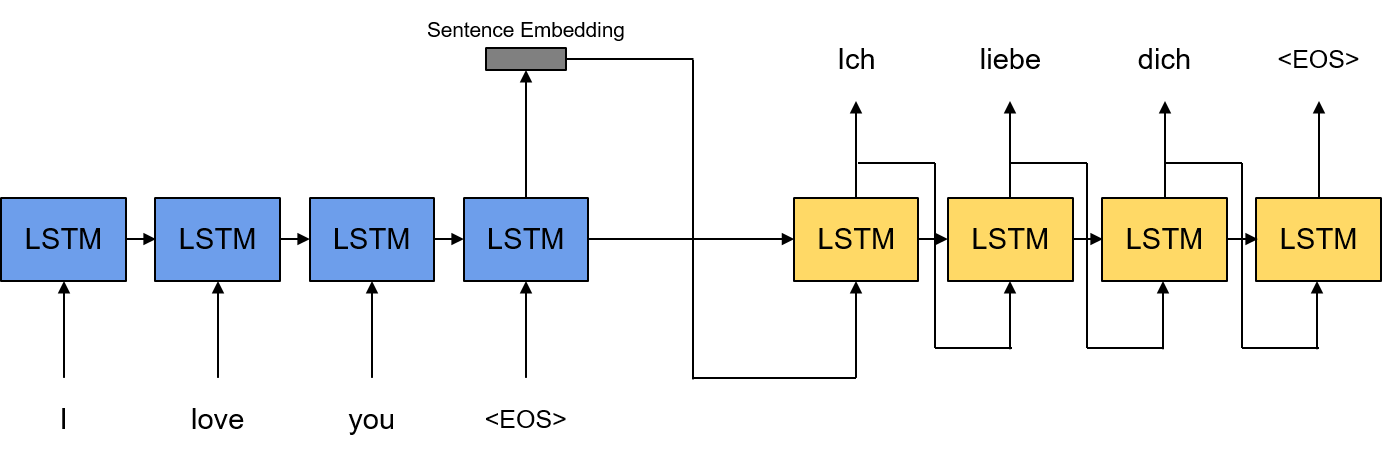
그림은 기본적인 Encoder-Decoder 모델을 나타낸 것이다. Encoder-Decoder 모델은 기계 번역에서 처음으로 사용하기 시작한 모델이다. Encoder와 Decoder를 각각 RNN(그림에서는 LSTM을 사용했지만) 셀로 구성한다. Encoder는 순차적으로 번역하고자 하는 문장의 시퀀스를 입력으로 받게 되고 문장을 고정된 길이의 벡터로 임베딩을 하게 된다. RNN 인코더의 경우 입력 시퀀스의 마지막 타임 스텝의 입력, 여기서는
이렇게 생성된 문장 임베딩은 다시 RNN 디코더의 첫번째 타임 스텝의 입력으로 들어가게 되고 인코더의 마지막 타임 스텝의 RNN Hidden State Vector는 RNN 디코더의 첫번째 타임 스텝의 Hidden State Vector로 들어가게 된다. 이렇게 입력 문장 임베딩 및 Hidden State Vector를 받은 디코더는 순차적으로 문장을 생성하여 결국 번역된 문장을 완성하게 된다.
간단하게 정리하면 현재 타임 스텝의 디코더 출력 \(y_i\)를 생성하기 위해서는 인코더에 입력되는 문장 시퀀스 \(\mathbf{x}\)와 이전 타임 스텝들의 디코더 출력 시퀀스 \(\{ y_1, \cdots, y_{i-1}\}\) 및 첫번째 타임 스텝의 입력 \(y_0\)이 Conditioning되는 조건부 확률 \(p(y_i \vert y_0,\cdots, y_{i-1}, \mathbf{x})\)는 RNN Encoder-Decoder 모델에서 다음과 같이 모델링될 수 있다.
\[\begin{align*} p(y_i \vert y_0,\cdots, y_{i-1}, \mathbf{x}) & = g(y_{i-1}, s_i) \\ s_i & = f(y_{i-1}, s_{i-1}) \end{align*}\] \[\begin{align*} \text{where} \ y_0 & = \text{Enc}(\mathbf{x}) \\ s_0 & = h_{T_{\mathbf{x}}} \end{align*}\]Attention Mechanism
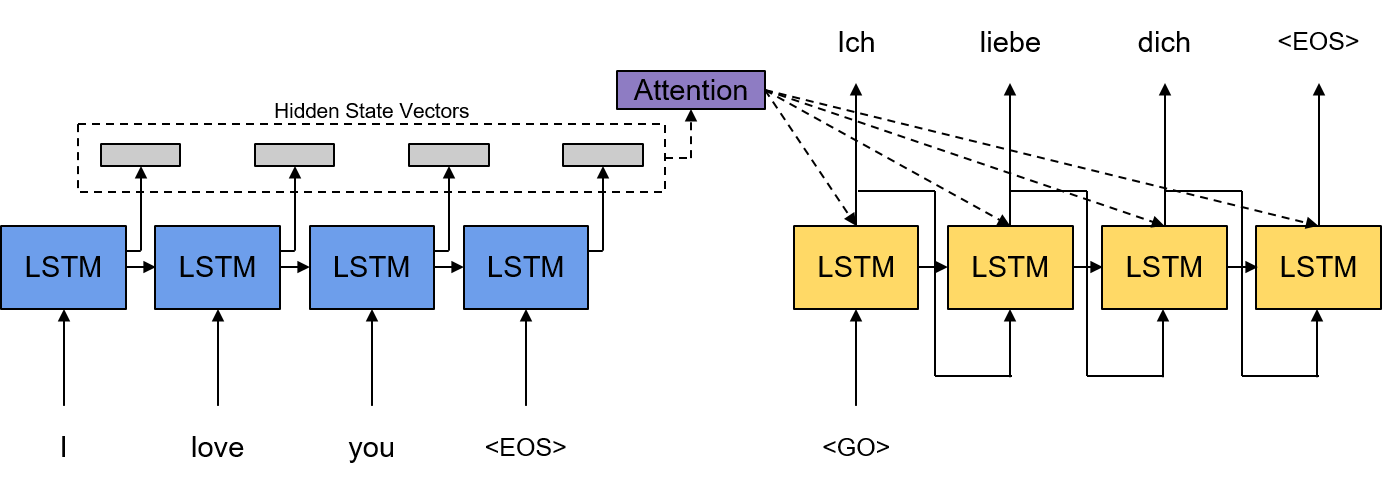
그 다음 그림은 기본 Encoder-Decoder 모델에 Attention Mechanism을 추가한 것을 나타낸다. Attention Mechanism은 문장을 하나의 고정된 길이의 벡터로 임베딩하는 것을 부정하는 과정에서 연구가 시작된 모델이다. 문장을 구성하는 모든 단어들을 각각 임베딩하여 디코더가 특정 타임 스텝에서 어떤 단어에 더 집중하여 현재 타임 스텝의 출력을 생성할지에 Attention Mechanism이 도움을 주게 된다. Tacotron은 Attention Mechanism으로 Bahdanau Attention을 사용하였으며 Bahdanau Attention에 대한 정리는 다음의 링크에서 확인할 수 있다.
간단하게 정리하자면 Bahdanau Attention 같은 경우는 이전 타임 스텝의 디코더 Hidden State Vector와 인코더의 Hidden State Vector 시퀀스를 입력으로 받아서 다음 현재 타임 스텝에서의 Context Vector를 생성한다. 이렇게 생성된 Context Vector는 이전 타임 스텝의 Hidden State Vector와 함께 사용되어 디코더가 현재 타임 스텝의 출력을 생성하게 된다.
좀 더 간단하게 정리하면 다음과 같다. Attention Mechanism을 적용하는 경우 조건부 확률 \(p(y_i \vert y_0,\cdots, y_{i-1}, \mathbf{x})\)는 RNN Encoder-Decoder 모델에서 다음과 같이 모델링될 수 있다.
\[\begin{align*} p(y_i \vert y_0,\cdots, y_{i-1}, \mathbf{x}) & = g(y_{i-1}, s_i, c_i) \\ s_i & = f(y_{i-1}, s_{i-1}, c_i) \end{align*}\] \[\begin{align*} \text{where} \ y_0 & = \text{<Go> Token}, \\ s_0 & = \mathbf{0} \\ c_i & = \text{Attn}(s_{i-1}, [h_1, \cdots, h_{T_{\mathbf{x}}}]) \end{align*}\]참고로 아래 그림처럼 Attention Mechanism의 Memory로 인코더 Hidden State Vector 시퀀스가 아닌 인코더 출력 Vector 시퀀스를 사용할 수도 있다. Tacotron이 바로 그러한 사용의 예라고 할 수 있다.

Tacotron 모델 구조
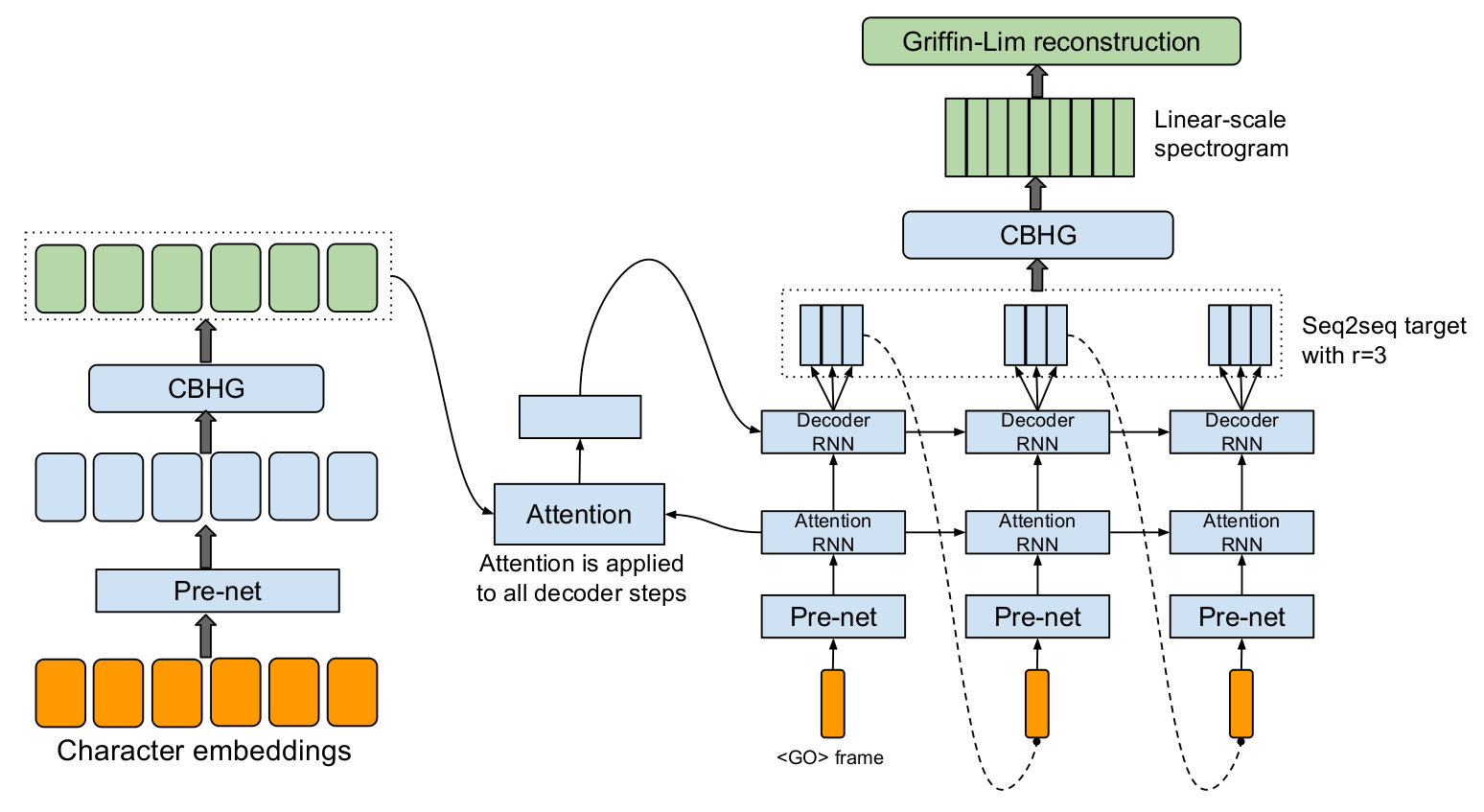
Tacotron의 모델 구조는 기본적으로 Attention Mechanism을 적용한 Encoder-Decoder 구조이다. 전체적인 모델 구조는 위 그림과 같다. 인코더는 입력 텍스트를 문자 단위로 임베딩을 한 문자 임베딩(Character Embedding)을 받게 되고 이렇게 입력된 문자 임베딩 Fully-Connected와 Dropout 레이어로 구성된 Pre-net을 거치게 된다. 그 이후에 CBHG라는 모델을 거치고 나서 생성된 시퀀스를 Attention에 사용하게 된다.
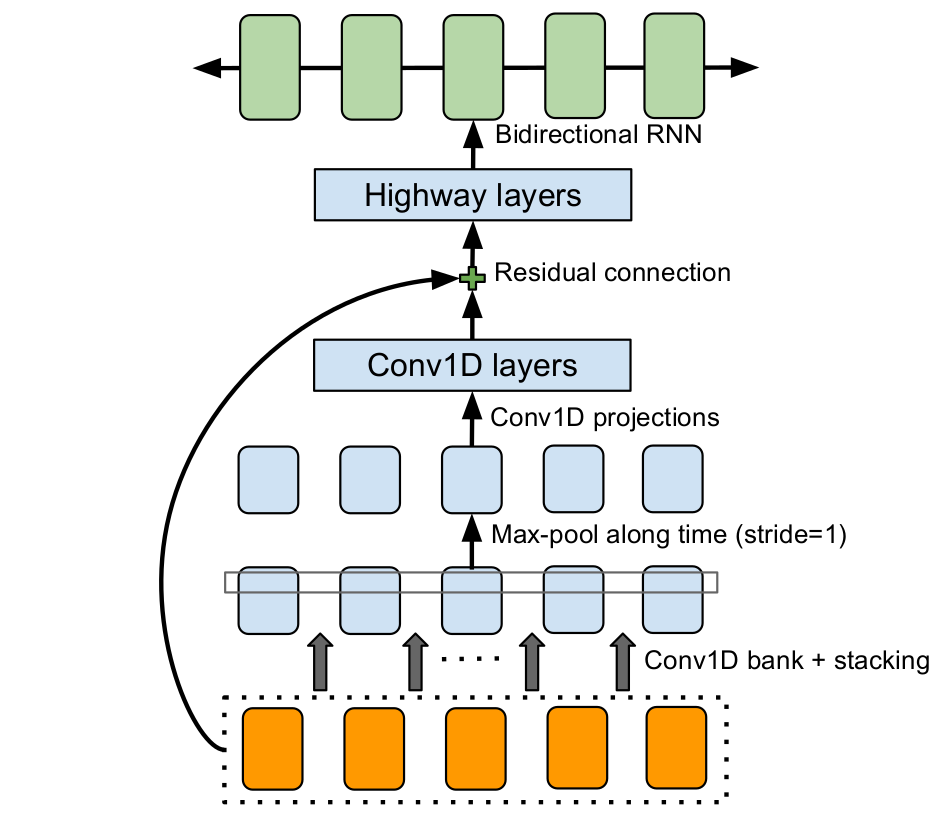
위 그림은 CBHG 모델을 나타낸 것이다. CBHG는 Convolution Bank + Highway + GRU의 약어이며 1D Convolution Bank와 Highway 네트워크, 그리고 Bidirectional GRU로 이루어져 있다. CBHG에 입력으로 들어가게 되면 시퀀스 타임 스텝 축을 따라서 1D Convolution이 이루어지는데 이 때 Convolution Kernel이 여러 사이즈를 가진 여러 종류가 사용되게 된다.
Convolution Bank에 대해서 추가적인 예시를 들어보면, 먼저 인코더의 경우 Kernel 사이즈를 1부터 16까지 16개를 사용하게 되고 디코더의 PostNet에 사용되는 CBHG의 경우 Kernel 사이즈를 1부터 8까지 8개를 사용하게 된다. 각각의 Kernel을 이용하여 1D Convolution을 수행한 후에 그 결과들을 Concat하여 다음 단계로 넘기게 된다.
Convolution Bank를 거친 후에는 다시 타임 스텝의 축을 따라 Max Pooling이 수행되게 된다. 그 다음 다시 1D Convolution을 거친 이후에 입력 레이어와 Residual Connection을 만들고 Highway 레이어로 넘어간다. 참고로 논문에서는 각각의 1D Convolution 이후에 Batch Normalization을 수행하였다고 한다. Batch Normalization에 대해서는 다음의 링크를 참조하면 된다.
Highway Network는 Gating 구조를 사용하는 Residual 네트워크이다. Residual 네트워크는 간단하게 다음과 같이 표현할 수 있다.
\[\text{Residual}(x) = R(x) + x\]입력 \(x\)와 출력 \(R(x)\)를 더함으로써 Residual 네트워크를 구성할 수 있다. 입력과 출력을 더하는 방식의 Residual 구조는 Vanishing Gradient 문제를 해결하기 위하여 고안된 구조인데 Residual 네트워크의 Backpropagation을 구하게 되면 \(R(x)\)를 생략하여 입력으로 바로 Backpropagation을 전달할 수 있기 때문에 이런 구조가 고안되었다고 볼 수 있다.
다만 Highway 네트워크에서는 이러한 Residual을 좀 다르게 구성하게 된다. Gating을 통해서 현재 Residual의 비율을 모델이 자동으로 어느 정도로 할 지 결정하게끔 구성한다.
\[\text{Highway}(x) = T(x) * H(x) + (1-T(x)) * x\]이 때 \(T(x)\)를 Transform Gate라고 하는데 여기서 중요한 점은 \(T(x)\)의 Bias는 무조건 -1과 같이 음수로 초기화를 해야한다.
Highway 네트워크를 거친 이후에는 Bidirection GRU를 거치게 된다. 여기서 Forward 시퀀스와 Backward 시퀀스를 Concat하여 출력하게 된다.
디코더는 인코더와 마찬가지로 입력에 대해서 Pre-net을 지난 후에 Attention RNN 셀과 Decoder RNN 셀들을 거치게 된다. Attention RNN 셀은 GRU 셀로 구성되고 Decoder RNN 셀은 Residual GRU Cell이 두 층으로 쌓여있는 구조이다.
디코더는 최종적으로 Mel-Spectrogram을 출력하게 되는데 여기서 저자들이 중요하다고 강조한 점이 있다. 바로 Reduction Factor \(r\)을 이용하여 여러 프레임을 동시에 생성한다는 것이다. 그림에서는 Reduction Factor가 3으로 설정되어 있다. 즉, 디코더는 한 타임 스텝에서 3개의 프레임에 해당하는 Mel-Spectrogram을 생성한다는 것이다. 이렇게 해도 되는 이유는 바로 음성 신호의 연속성 때문이다. 음성 신호는 여러 프레임에 거쳐서 하나의 발음이 수행되기 때문에 이러한 가정이 유의미한 것이다.
이렇게 생성된 Mel-Spectrogram은 PostNet에 해당하는 CBHG를 거치게 되며 최종적으로 Linear-Spectrogram을 생성하게 된다. Linear-Spectrogram은 Griffin-Lim Algorithm이라는 음성 재구성 알고리즘을 통해서 음성으로 변환되게 된다.
Tacotron의 트레이닝 및 생성
Tacotron은 Attention Mechanism을 포함한 Encoder-Decoder 구조이기 때문에 트레이닝 및 생성 방식은 일반 Encoder-Decoder 모델과 같다. 먼저 트레이닝의 경우에는 입력 텍스트 및 타겟 오디오를 전처리하여 Mel-Spectrogram과 Linear-Spectrogram을 준비해놔야 한다. 즉 정리하자면, 입력은 텍스트, 타겟은 Mel-Spectrogram 및 Linear-Spectrogram을 필요로 하게 된다.
Loss 구성은 다음과 같다. 먼저 디코더의 출력인 Mel-Spectrogram 출력과 타겟 Mel-Spectrogram과의 L1 Distance를 구한다. Mel-Spectrogram은 2차원 Feature라는 것에 주의하면서 L1 Distance를 구해야 할 것이다. 이렇게 구한 Distance를 Mel-Loss로 정의한다. Mel-Loss를 TensorFlow 코드를 통해서 구현하면 다음과 같다.
mel_loss = tf.reduce_mean(tf.abs(mel_outs - mel_targets))
마찬가지 방법으로 Linear-Spectrogram 출력과 타겟 Linear-Spectrogram과의 L1 Distance를 구한다. 마찬가지로 Linear-Loss로 정의한다. TensorFlow 코드는 아래와 같다.
lin_loss = tf.reduce_mean(tf.abs(lin_outs - lin_targets))
최종적인 Tacotron의 Loss는 Mel-Loss 및 Linear-Loss를 더한 값을 사용하게 된다.
loss = mel_loss + lin_loss
트레이닝 및 생성 과정에서의 중요한 차이로는 모델 인퍼런스 방식에 있다. 트레이닝은 디코더의 인퍼런스 과정에서 디코더의 입력으로 타겟 Mel-Spectrogram을 넣게 된다. 정확하게는 Reduction Factor가 3이므로 타겟 Mel-Spectrogram 3개 프레임마다 잘라서 마지막 프레임만을 입력으로 넣어줘야 할 것이다.
생성은 원래 디코더의 의도와 같이 이전 타임 스텝에서 생성한 프레임 3개 중 마지막 프레임을 현재 타임 스텝의 디코더 입력으로 사용해야 한다.
Optimizer는 간단하게 Adam Optimizer를 사용하였다고 한다. Learning Rate는 Decaying할 필요는 없는 모양이며 그저 Learning Rate를 특정 트레이닝 스텝마다 순차적으로 줄여나가는 방식으로 진행하였다고 주장한다.
Tacotron의 성능
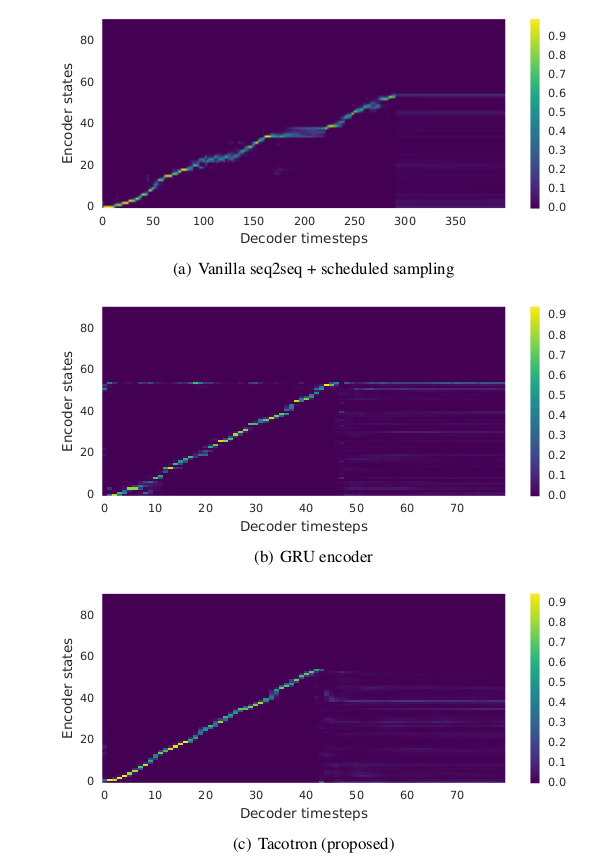
저자들은 자신들의 모델 성능을 비교하기 위하여 Alignments 그래프를 보여준다. 비교를 위해서 사용된 모델은 Vanilla Seq2Seq + Scheduled Sampling 모델 및 GRU Encoder를 사용한 모델이다. Alignments 결과는 아래 그림과 같다. Tacotron의 Alignments가 더 뚜렷하게 잘 나오는 것을 확인할 수 있다.
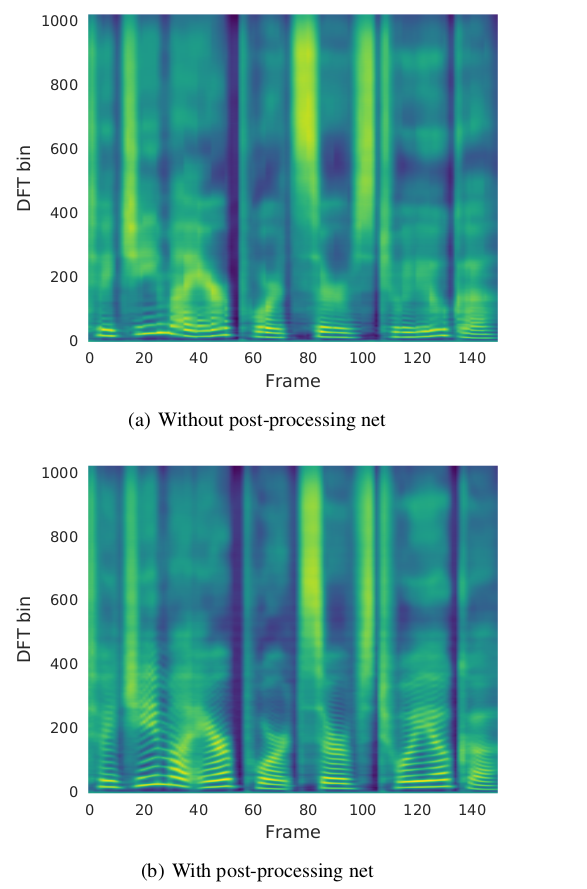
그 다음으로 디코더와 PostNet을 나눠서 Mel-Spectrogram 및 Linear-Spectrogram을 따로 생성하는 이유에 대한 결과이다. 아래 그림에서 (a)는 PostNet 없이 바로 Linear-Spectrogram을 생성하는 모델이고, (b)는 제안된 모델이며 두 모델의 차이는 Linear-Spectrogram을 생성하는 경우에 중간 과정으로 Mel-Spectrogram을 생성하느냐 아니냐 라고 말할 수 있다. 저자들은 자신들의 모델인 (b)가 DFT bin이 100에서 400인 구간에서 더 많은 Harmonic을 생성하고 있다고 주장하며 이것이 성능 차이를 만든다고 말한다.
그 다음 결과는 이전 TTS 모델들과의 MOS 스코어의 비교이다. MOS 스코어는 음성 합성의 특성상 많이 사용되는 지표이다. 크라우드 소싱을 통하여 생성된 음성이 얼마나 사람 목소리에 가까운지를 1에서 5점 사이로 매겨서 구하는 점수이다. 여기서 Concatenative 보다는 성능이 떨어지지만 Parametric은 상회하는 성능을 보인다는 것을 확인할 수 있다.

Tacotron의 음성 샘플은 링크에서 확인할 수 있다.