이번 포스트에서는 최근 자연어 처리 분야에서 가장 많이 활용되고 있는 거대 언어 모델의 아이디어를 처음으로 제안했단 BERT에 대해서 다룬다. BERT는 등장하자마자 획기적이라는 평가를 받았던 언어 모델이며 기존에 존재했던 대부분의 자연어 처리 태스크에서 SOTA(State-of-the-Art) 수준을 달성하는 강력한 모습을 보였었다. BERT의 구조와 훈련 방식을 따라가는 구성으로 이번 포스트의 내용을 다뤄볼 계획이다.
목차
기존 언어 모델 소개
거대 언어 모델 연구는 지금까지 언어 모델에 대한 사전 훈련(Pre-Training)을 바탕으로 토큰 표현(Representation)을 잘 획득하고 이를 통해 다양한 자연어 처리 태스크를 수행하는 것을 목적으로 수행되어 왔다. 이러한 방향의 언어 모델 연구 역사는 꽤나 오래되었지만 크게 3가지 공통된 방향성이 존재한다.
ELMo
우선 비지도 특징 기반 접근이 있다. 이 접근은 비지도 기반 특징화를 통해 단어 또는 토큰의 좋은 표현을 획득하려고 했던 연구들을 말한다. 일반적으로는 정방향(Left-to-Right) 언어 모델링 기반 목적 함수 최적화를 통해 단어/토큰 표현을 획득했었고 이런 방식은 정방향 언어 모델링은 문장 임베딩(Sentence Embedding), 더 나아가 문단 임베딩(Paragraph Embedding)으로 일반화되어 왔다.
ELMo(Embeddings from Language Models)는 이러한 비지도 특징 기반 접근의 대표적인 언어 모델이다. 기존의 연구들과는 다르게 ELMo는 문장 내에서 최대한 문맥 정보를 추출할 수 있는 방법을 통해 단어 표현을 고도화하고자 하였다. 우선 정방향 언어 모델링 뿐 아니라 역방향(Right-to-Left) 언어 모델링을 통한 정보를 둘다 활용하여 양방향(Bidirectorional) 언어 모델링을 구현하고자 하였다.
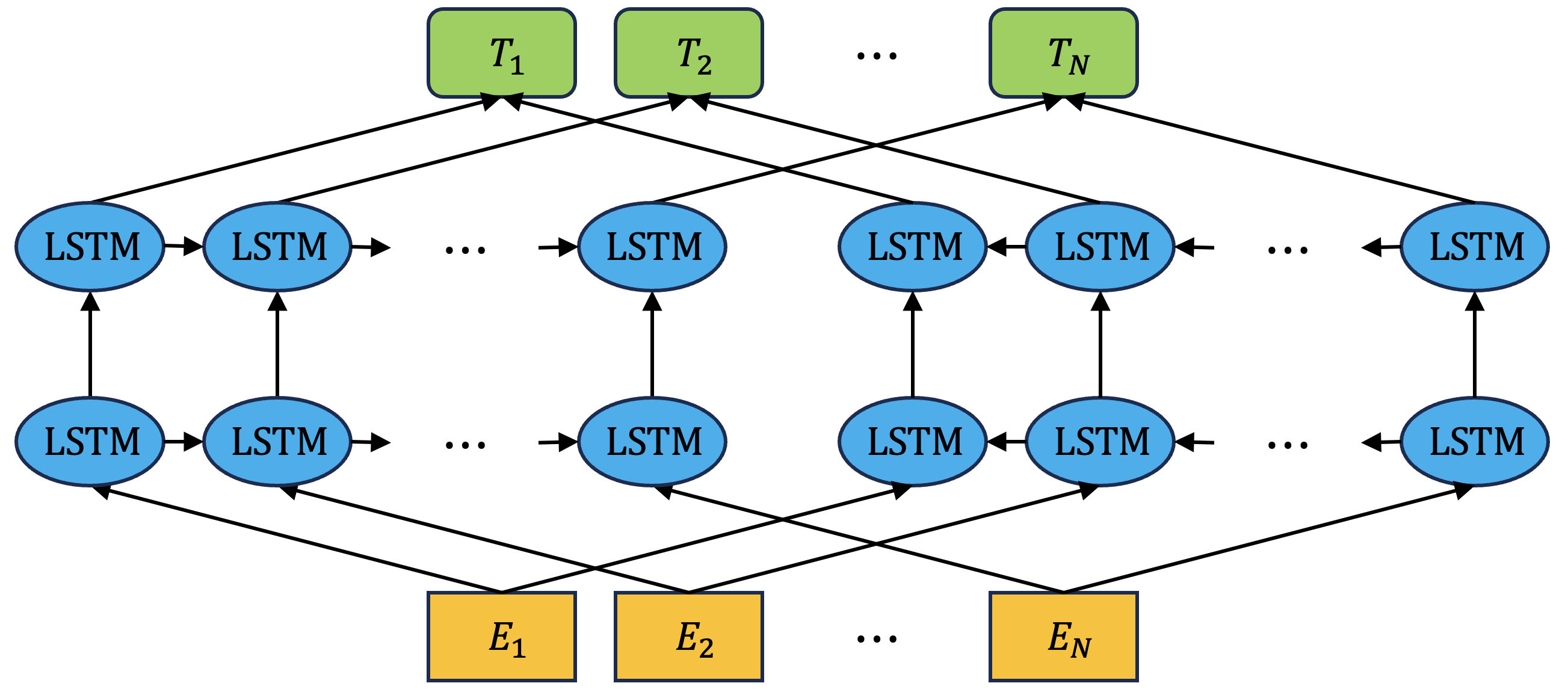
목적 함수 계산을 위한 ELMo의 양방향 언어 모델링은 다음과 같이 수행된다. 우선 아래와 같이 N개의 토큰이 주어졌다고 가정해 보자:
\[(t_1, t_2, \cdots, t_N).\]여기서 정방향 언어 모델링을 통한 토큰 시퀀스 확률 값은 다음과 같다:
\[p(t_1, t_2, \cdots, t_N) = \prod_{k=1}^N p(t_k | t_1, t_2, \cdots, t_{k-1}).\]마찬가지로 역방향 언어 모델링을 통한 토큰 시퀀스 확률 값도 계산할 수 있다:
\[p(t_1, t_2, \cdots, t_N) = \prod_{k=N}^1 p(t_k | t_{k+1}, t_{k+2}, \cdots, t_{N}).\]이러한 언어 모델링을 통해서 목적 함수는 Maximum Likelihood Estimation에 의하여 다음과 같이 정리될 수 있다:
\[\sum_{k=1}^N \left( \log p(t_k | t_1, \cdots, t_{k-1} ; \boldsymbol{\theta}) + \log p(t_k | t_{k + 1}, \cdots, t_N ; \boldsymbol{\theta}) \right).\]또한 ELMo는 LSTM 계층을 여럿 쌓은 스택에서 마지막 계층의 은닉 상태(Hidden State) 벡터만을 특징으로 사용하였던 기존의 접근과는 다르게 스택의 모든 계층의 으닉 상태 벡터를 활용하여 특징화를 수행한다. 이는 더 깊게 문맥 정보를 활용할 수 있다는 장점이 있다고 한다.
ELMo의 LSTM 계층이 L층으로 구성되어 있는 경우 토큰 \(t_k\)에 대한 표현 집합은 다음과 같다:
\[R_k = \left\{ \mathbf{x}_k, \overrightarrow{\mathbf{h}}_{k, j}, \overleftarrow{\mathbf{h}}_{k, j} | j=1,2, \cdots, L \right\}.\]여기서 \(\mathbf{x}_k\)는 토큰 \(t_k\)의 문맥에 독립적인 표현이다. 그리고 \(\overrightarrow{\mathbf{h}}_{k, j}, \overleftarrow{\mathbf{h}}_{k, j}\)는 각각 \(j\)번째 정방향/역방향 은닉 상태 벡터를 의미한다. 표현 집합은 이어 붙어서(Concatenation) 하나의 벡터로 형성되어 표현 집합을 새롭게 정의하게 된다.
\[R_k = \left\{ \mathbf{h}_{k, j} | j=1,2, \cdots, L \right\}.\]ELMo의 최종 표현은 이 표현 집합에 포함된 L개의 표현을 가중합을 통해 계산되어 Task-Specific한 계층의 입력에 활용되어 우리가 원하는 태스크에 활용된다.
이러한 과정은 ELMo의 모델 구조에서도 확인할 수 있다. LSTM 스택 2개가 각각 정방향과 역방향으로 주어진 토큰의 임베딩 시퀀스 \((E_1, E_2, \cdots, E_N)\)을 은닉 벡터 시퀀스로 인코딩을 수행하고 이 결과를 최종 은닉 벡터 시퀀스 \((T_1, T_2, \cdots, T_N)\)으로 결합하여 구성한다.
OpenAI GPT
그 다음으로는 비지도 파인 튜닝(Fine-Tunning) 접근이 있다. 파인 튜닝이란 사전 훈련된 모델의 가중치에 Task-Specific한 새로운 데이터를 사전 훈련용 데이터에 비해서 상대적으로 소량 활용하여 Task-Specific한 모델 가중치를 획득하는 작업을 말한다.
초기 연구들은 비지도 파인 튜닝 접근을 위하여 사전 훈련된 단어(토큰) 임베딩을 활용하는 정도였다. 반면 최근 연구들은 비지도 방식을 통해서 문장, 또는 문서에 대한 임베딩 모델에 대해 사전 훈련을 시도하고 있다. 이러한 접근의 좋은 점은 매우 적은 파라미터만이 업데이트되는 정도라서 파인 튜닝 과정이 매우 짧다는 점이다.
OpenAI GPT는 이러한 문장 수준의 사전 훈련을 통해서 GLUE 벤치마크에서 다양한 문장 수준의 태스크에 대해 SOTA를 달성하였다.
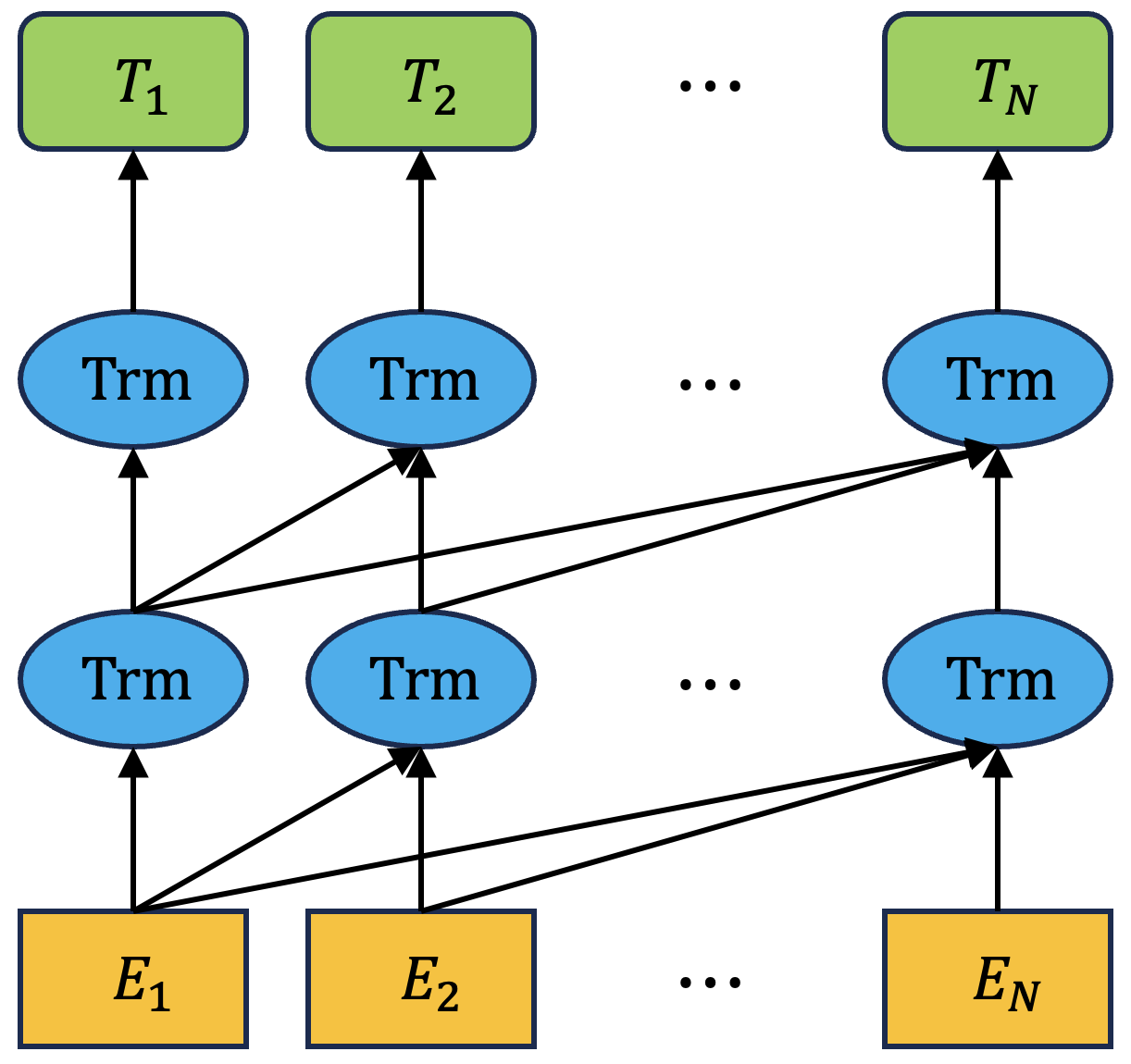
GPT(Generative Pretrained Transformers)는 이름에서 알 수 있듯 Transformer 구조로 되어 있다. GPT의 컨셉은 기본적으로 준지도 학습(Semi-Supervised Learning)이다. 이는 비지도 사전 훈련과 지도 학습 기반의 지도 파인 튜닝을 활용하기 때문이다.
GPT의 비지도 사전 훈련은 다음과 같은 목적 함수를 최적화하는 방식으로 진행된다. 우선 주어진 레이블이 없는 토큰들의 말뭉치 \(\mathcal{U} = (u_1, u_2, \cdots, u_n)\)에 대하여 다음의 Likelihood Function을 목적 함수로 한다:
여기서 k는 문맥 윈도우 크기이다. 목적 함수의 조건부 확률은 언어 모델을 통해서 계산된다. GPT 논문의 저자들은 이 조건부 확률 계산을 위하여 다층 Transformer 디코더를 사용하였다고 한다.
그 다음으로 GPT의 지도 파인 튜닝은 다음과 같이 진행된다. 우선 주어진 레이링된 데이터싯 \(\mathcal{C}\)를 가정하자. 이 데이터셋의 각 인스턴스는 입력 토큰 시퀀스 \((x_1, x_2, \cdots, x_m)\)과 레이블 \(y\)로 구성된다.
Transformer 디코더의 최종 출력 \(\mathbf{h}\)은 이후 Task-Specific 추가 선형 계층에 입력되어 최종적으로 레이블 \(y\)를 다음과 같이 예측한다:
\[p(y|x_1, \cdots, x_m) = \text{softmax}(\mathbf{hW}_y).\]이는 Maximum Likelihood Estimation을 통해 다음과 같은 목적 함수 계산에 활용된다:
\[\sum_{\mathbf{x}, y} \log p(y | x_1, \cdots, x_m).\]지도 데이터를 통한 전이 학습
지도 데이터(Supervised Data)를 통한 전이 학습(Transfer Learning) 과정은 위에서 설명하였던 ELMo 및 GPT에서도 Task-Specific한 계층의 학습을 위하여 활용되어 왔다. 이런 방식을 통해 거대 말뭉치로부터 사전 훈련된 모델을 활용하여 적은 학습 비용을 바탕으로 파인 튜닝을 수행하여 자연어 추론이나 기계 번역 등의 새로운 태스크에 대해 좋은 성능을 낼 수 있는 모델을 전이 학습을 시킬 수 있다.
이러한 전이 컴퓨터 비전 분야에서 증명되어 왔다. 이미지넷(ImageNet) 등과 같은 거대 데이터를 통해 사전 훈련된 모델에 파인 튜닝을 통한 전이 학습은 그 학습 방법이 유효하다는 것을 성능으로 확인할 수 있다.
BERT 소개
BERT(Bidirection Encoder Representations from Transformers)는 구글에서 2018년에 발표한 거대 언어 모델이다. 이름에서 알 수 있듯 BERT는 Transformer 기반의 인코더 구조를 지닌 언어 모델이며 따라서 토큰, 또는 문장, 더 나아가 문서의 은닉 표현(Hidden Representation)을 학습하는 모델이라고 볼 수 있다.
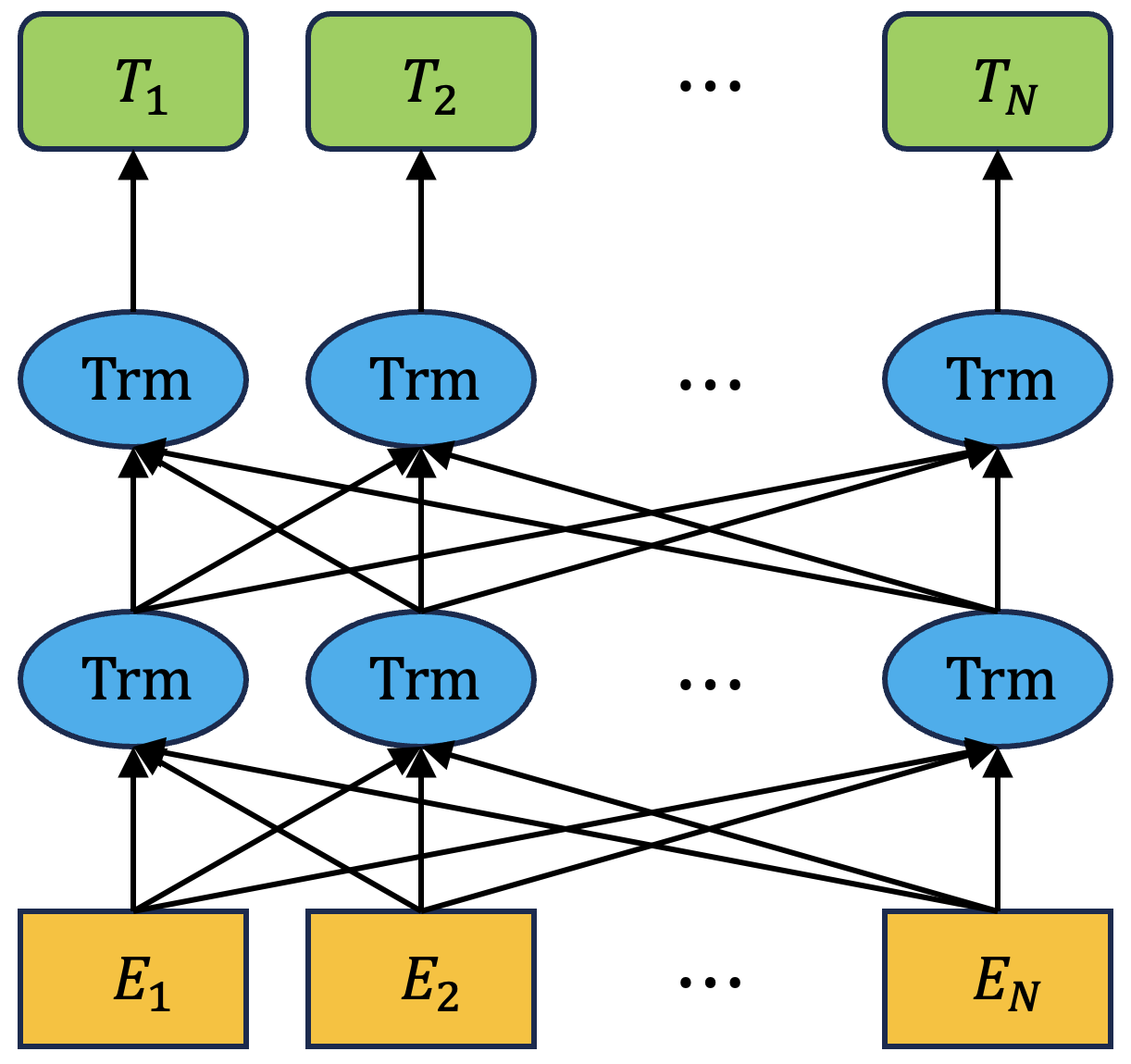
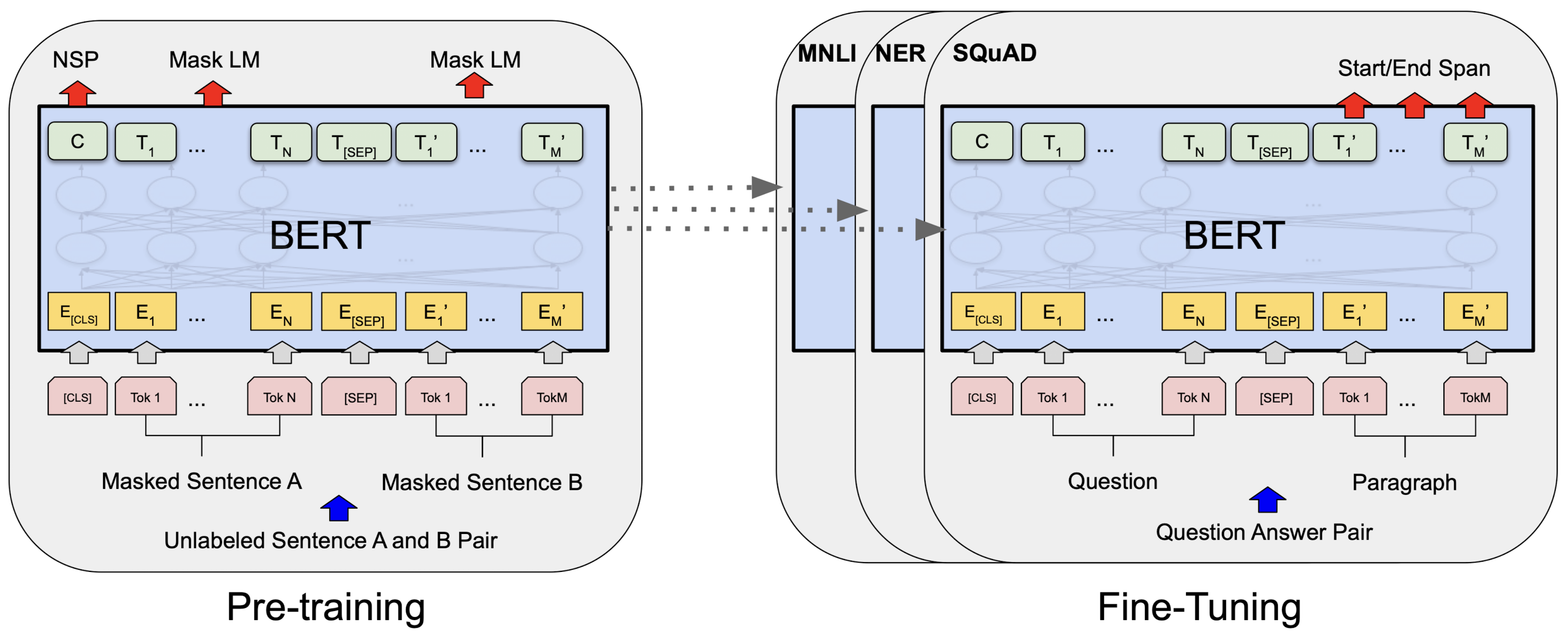
위 그림은 BERT의 구조를 간단히 설명하는 그림이다. 위 그림에서 확인할 수 있듯이 기본적으로 Transformer로 구성되어 있음을 확인할 수 있으며 Transformer의 특별한 구조를 활용하여 양방향으로의 정보를 활용하여 각 토큰의 인코딩을 수행하는 것을 볼 수 있다.
BERT는 기존 거대 언어 모델들과 마찬가지로 레이블이 없는 말뭉치를 통해 사전 훈련을 수행하고 이렇게 사전 훈련이 된 모델을 바탕으로 사용자가 원하는 특정 태스크에 대해 파인 튜닝을 수행하여 최종적인 태스크에 특화된 모델을 획득하는 과정을 거친다. BERT는 이름에서 알 수 있듯 기본적으로 입력 문장에 대해서 인코딩을 수행하여 은닉 벡터 표현을 획득하고 이렇게 획득한 벡터 표현을 바탕으로 태스크에 특화된 새로운 인공 신경망 계층을 추가하여 파인 튜닝을 수행한다.
BERT의 구조
BERT의 구조는 위에서 말했듯이 다층 양방향 Transformer 인코더 형태이다. BERT의 저자들은 이 인코더 구조를 구성하는 Transformer는 원래의 Transformer에서 변화없이 그대로 사용하였다고 한다. Transformer에 대해서 더 자세히 알아보고 싶으면 이전 포스트를 참고하면 된다.
저자들은 BERT 모델을 크기별로 크게 2개를 제안했다. 먼저 BERT BASE이다. BERT BASE 말 그대로 기본 BERT이며 Transformer 스택 계층 수 \(L\)을 12로, 은닉 표현 사이즈 \(H\)를 768로, Self-Attention Head 수 \(A\)를 12로 설정한 모델이다.
그 다음으로는 BERT LARGE가 있다. BERT LARGE는 \(L\)을 24로, \(H\)를 1024로, \(A\)를 16으로 설정한 모델이다. 아래 표에 두 모델에 대해서 간단히 정리를 해보았다.
| L | H | A | 파라미터 수 | |
|---|---|---|---|---|
| BERT BASE | 12 | 768 | 12 | 110M |
| BERT LARGE | 24 | 1024 | 16 | 340M |
BERT BASE에 비해서 BERT LARGE는 파라미터 수가 약 3배 정도 되는 340만 정도이다. 원래 저자들이 의도한 모델은 BERT LARGE이지만 BERT BASE는 GPT와 비교를 하기 위하여 만든 모델이라는 듯 하다.
BERT의 입/출력 표현
BERT의 입/출력 표현 방법은 다양한 NLP 태스크를 수행하기 위한 형태로 설계되었다. 단순히 토큰 표현들 뿐 아니라 단일 문장, 그리고 질의 응답 태스크 등을 수행하기 위한 이중 문장을 입력받을 수 있는 형태이다.
우선 모든 입력 토큰은 WordPiece라는 이름의 임베딩을 사용했다. WordPiece에 대해서는 나중에 자세히 다뤄보기로 한다. 어쨌든 모든 토큰들은 이 WordPiece 임베딩을 통해서 벡터 형태로 변환된다. 또한 추가적으로 모든 문장의 첫 번째 토큰은 [CLS] 토큰이라는 것을 붙여서 사용한다. 이 [CLS] 토큰은 문장 전체의 인코딩을 위한 토큰으로 문장 분류 등의 태스크에 활용될 수 있다.
이중 문장이 토큰 시퀀스로 입력되어 모델에 들어오는 경우 이 문장들을 구분하는 방법이 필요하다. BERT에서는 두 가지 방법을 통해서 이 구분을 수행한다. 먼저 구분자인 [SEP] 토큰을 중간에 껴넣어서 구분하는 방법이다. 두 번째는 각 토큰 임베딩에 추가로 문장 A에 속한 것인지 문장 B에 속한 것인지를 나타내는 임베딩 벡터를 이어 붙여서 모델이 구분할 수 있도록 하는 방법이다.
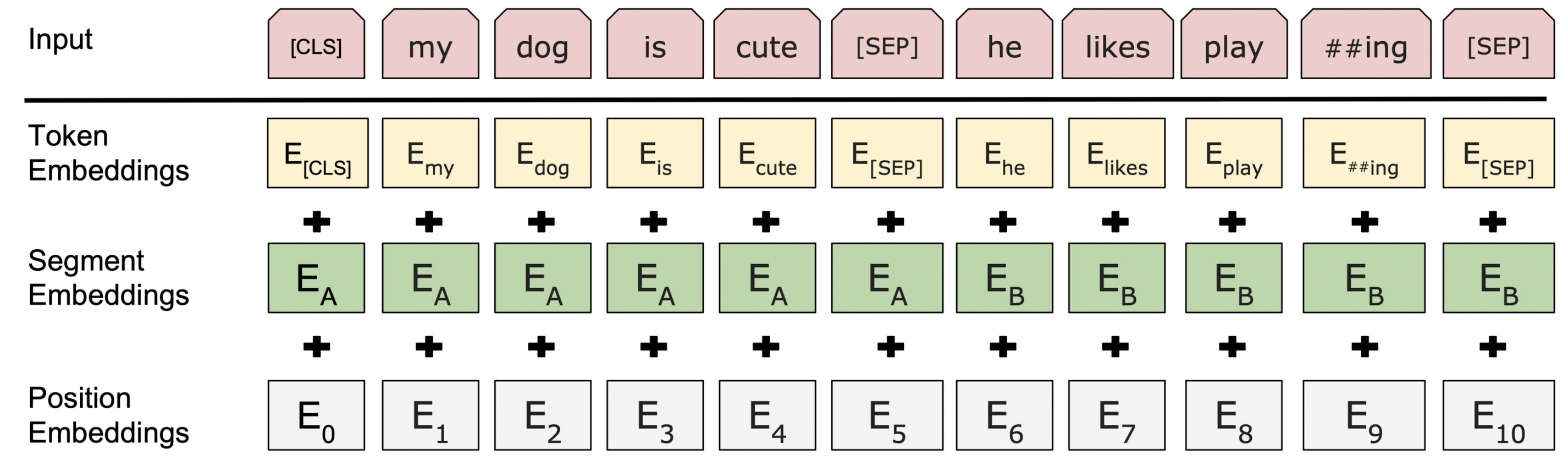
위 그림은 BERT의 입력 표현 방법을 나타내는 그림이다. [SEP] 토큰을 통해 두 문장이 구분되고 있으며 또한 Segment 임베딩을 통해서 각각의 토큰이 첫 번째 문장(A)에 속한 것인지 두 번째 문장(B)에 속한 것인지를 나타내고 있다. 물론 맨 앞에는 [CLS] 토큰을 통해서 입력 문장이 시작됨을 나타내고 있다. 마지막으로 각 토큰들에 대한 위치 임베딩까지 더해진다. 이 세 가지의 임베딩 벡터들의 합을 통해서 각 토큰의 표현 벡터를 계산한다.
BERT의 사전 훈련
기존의 언어 모델들과 다르게 BERT는 정방향 또는 역방향의 사전 훈련을 수행하지 않는다. 대신 두 가지의 비지도 태스크를 통해서 사전 훈련이 진행된다. 두 가지 태스크는 각각 마스크 언어 모델(Masked LM, MLM)과 다음 문장 예측(Next Sentence Prediction, NSP)이다. BERT의 사전 훈련 과정은 두 가지 사전 훈련 태스크에 대해서 태스크에 특화된 추가 인공 신경망 계층을 학습하는 방식으로 진행된다.
태스크 (1) - 마스크 언어 모델
BERT는 기존의 정방향/역방향 모델들과는 다른 진정한 의미에서의 양방향 모델이라고 저자들은 주장한다. BERT와는 다르게 기존의 양방향 모델이라고 여겨지던 이전 모델들은 단순히 정방향/역방향의 표현을 이어 붙이는 정도의 얕은 수준의 양방향 모델이었고 진정한 의미의 양방향 모델은 BERT 뿐이라는 것이다.
이러한 BERT의 양방향성을 잘 활용하여 사전 훈련을 수행하기 위해서 단순하게 입력 토큰 시퀀스에서 임의로 선택된 토큰들을 마스킹하여 BERT 모델로 하여금 마스킹된 토큰이 무엇인지 예측하는 방식의 사전 훈련을 제안한다. 이러한 방식의 사전 훈련을 마스크 언어 모델이라고 한다.
저자들은 마스크 언어 모델 방식을 통해 사전 훈련을 진행하기 위해서 다음과 같은 방식의 마스킹 방법을 활용했다. 훈련용 데이터를 생성하는 과정에서 전체 토큰들 중 15%의 토큰을 랜덤하게 추출하여 마스킹에 활용한다. 이렇게 추출된 토큰들 각각은 80%는 [MASK] 토큰으로, 10%는 임의의 다른 토큰으로, 그리고 마지막 10%는 변화없이 그대로 둔다.
이렇게 마스킹된 말뭉치를 바탕으로 BERT는 사전 훈련이 진행된다. 말뭉치로부터 추출된 문장의 토큰 시퀀스를 입력받은 모델은 각 토큰 시퀀스에 대한 표현 벡터를 생성하고 이를 통해서 마스크 언어 모델 태스크를 수행한다. 이는 마스크 언어 모델 태스크에 특화된 인공 신경망 모델 계층을 추가하여 진행된다.
태스크 (2) - 다음 문장 예측
마스크 언어 모델이 토큰 단위의 양방향 언어 모델링을 수행하지만 이것만으로는 한계가 있다. 많은 자연어 처리 태스크가 단순히 토큰 단위의 태스크를 넘어서 문장 단위의 이해가 필요한 태스크이기 때문이다. 질의 응답(Question Answering, QA) 또는 자연어 추론(Natural Language Inference, NLI)이 그 예시이다. 이러한 태스크들은 주어진 두 문장 사이의 관계를 이해해야만 하는 태스크들이다.
이러한 관계를 학습시키기 위하여 BERT는 사전 훈련 과정에서 다음 문장 예측 태스크를 수행한다. 다음 문장 예측은 다음과 같은 과정을 통해서 진행된다. 우선 훈련용 데이터셋으로부터 문장 2개를 추출한다. 두 문장은 각각 문장 A, B로 지칭한다. 문장 A, B를 추출하는 과정에서 50%는 문장 B가 실제로 문장 A 다음에 등장하는 문장으로, 나머지 50%는 문장 A와 관계없는 문장으로 추출한다.
문장 B가 실제로 문장 A 다음에 추출된 경우에 레이블은 IsNext, 그렇지 않은 경우에는 NotIsNext로 레이블을 설정하여 이를 예측하도록 하는 태스크 특화된 인공 신경망 계층을 추가하여 사전 훈련을 수행한다. 사전 훈련을 위한 손실 함수의 계산은 마스크 언어 모델을 위한 손실 함수와 다음 문장 예측을 위한 손실 함수의 평균으로 계산한다.
사전 훈련 데이터
사전 훈련을 위한 데이터는 기존 거대 언어 모델의 사전 훈련에 활용되었던 데이터셋을 활용하였다. 8억 단어로 구성된 BooksCorpus와 25억 단어로 구성된 영문 위키피디아를 말뭉치로 활용하여 사전 훈련을 진행하였다. 특히 영문 위키피디아의 경우 다른 말뭉치들처럼 단어 단위로 섞인 말뭉치가 아닌 문서 단위의 말뭉치라는 점이 매우 중요한 부분이라고 저자들은 주장한다.
BERT의 파인 튜닝
사전 훈련이 진행된 이후 BERT는 파인 튜닝을 통해서 태스크 특화된 모델을 획득한다. BERT의 파인 튜닝은 BERT의 인코딩된 은닉 벡터 표현을 새로운 태스크 특화된 계층에 통과시켜 최종적으로 태스크에 따라 원하는 출력으로 변환한다. 이 과정에서 파인 튜닝은 BERT의 가중치를 고정시키지 않고 End-to-End로 전체 모델(BERT + 새로운 계층)의 가중치를 학습시킨다.
파인 튜닝은 상대적으로 사전 훈련에 비해서 훨씬 비용이 저렴하다. 따라서 사전 훈련된 BERT 모델만 있다면 우리가 원하는 태스크에 특화된 모델을 획득하기 위하여 적절한 파인 튜닝만을 도입하면 된다.
BERT의 성능 평가
저자들은 파인 튜닝을 통해서 획득한 BERT의 성능을 총 11개의 NLP 태스크에 대해서 공개하고 있다.
GLEU
| System | MNLI-(m/mm) | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | Average |
|---|---|---|---|---|---|---|---|---|---|
| 392k | 363k | 108k | 67k | 8.5k | 5.7k | 3.5k | 2.5k | - | |
| Pre-OpenAI SOTA | 80.6/80.1 | 66.1 | 82.3 | 93.2 | 35.0 | 81.0 | 86.0 | 61.7 | 74.0 |
| BiLSTM+ELMo+Attn | 76.4/76.1 | 64.8 | 79.8 | 90.4 | 36.0 | 73.3 | 84.9 | 56.8 | 71.0 |
| OpenAI GPT | 82.1/81.4 | 70.3 | 87.4 | 91.3 | 45.4 | 80.0 | 82.3 | 56.0 | 75.1 |
| BERT BASE | 84.6/83.4 | 71.2 | 90.5 | 93.5 | 52.1 | 85.8 | 88.9 | 66.4 | 79.6 |
| BERT LARGE | 86.7/85.9 | 72.1 | 92.7 | 94.9 | 60.5 | 86.5 | 89.3 | 70.1 | 82.1 |
위 표는 GLEU 태스크에 대한 성능 평가 결과를 정리한 것이다. GLEU 태스크는 GLEU 데이터셋에 대해서 다양한 NLP 태스크를 수행하는 것을 포함한다. GLEU 태스크는 총 8가지가 있으며 단일 문장에 대한 태스크 2개(CoLA, SST-2), 문장 유사도 및 패러프레이징 태스크 3개(MRPC, QQP, STS-B), 그리고 자연어 추론 태스크 4개(MNLI, QNLI, RTE, WNLI)로 구성되어 있다.
GLEU 태스크를 수행하기 위해서 BERT의 출력 시퀀스에서 [CLS] 토큰에 대한 은닉 벡터를 문장에 대한 통합 표현 벡터로 활용하였다. 또한 BERT LARGE를 학습시키는 과정에서 데이터셋이 소량인 경우 파인 튜닝이 불안정하게 진행되는 문제가 있었어서 여러번 재시작을 통해 결과 모델을 획득하였다고 한다.
위 결과에서도 확인할 수 있듯이 BERT BASE 및 BERT LARGE 둘 다 기존 모델들을 상회하는 성능을 보였다. 평균 성능에서는 두 모델 각각 4.5%, 7.0%의 성능 상회를 확인할 수 있다. 여기서 주목할만한 것은 BERT BASE의 경우 OpenAI GPT와 Attention Masking을 제외하고는 모델 구조 및 파라미터 수가 거의 비슷하다는 점이다.
BERT LARGE는 BERT BASE와 비교하여 모든 태스크에 대해 성능을 훨씬 상회하고 있다. BERT LARGE는 BERT BASE에 비해서 더 모델 사이즈가 큰데 모델 사이즈가 어떤 영향을 주는지는 뒤에서 다뤄볼 것이다.
SQuAD
SQuAD(Standard Question Answering Dataset)는 이름에서 알 수 있듯이 질의 응답을 위한 표준적인 데이터셋이다. SQuAD는 1.1 버전과 2.0 버전이 있는데 1.1 버전은 크라우드소싱을 통해서 수집된 질의 응답 쌍 10만 쌍으로 구성되어 있다. 2.0 버전의 경우는 1.1 버전을 확장하여 주어진 문단 내에서 짧은 정답이 있지 않게끔 더욱 현실적이고 어렵게 만든 것이다.
SQuAD는 출처가 위키피디아인 주어진 문단과 질문을 받아서 해당 질문에 대한 답을 주어진 문단 내에서 찾아내는 태스크이다. SQuAD 태스크를 위해서 BERT는 입력 토큰 시퀀스를 다음과 같이 구성한다. 우선 주어진 다음 문장 예측 태스크에서처럼 질문 문장은 문장 A 임베딩과 함께, 문단은 문장 B 임베딩과 함께 구성하여 모델에 입력한다. 그리고 출력 표현 시퀀스 각각을 통해서 각각의 토큰이 정답에 속한 문장의 시작, 끝 부분일 확률을 계산하도록 한다.
이 계산은 다음과 같이 수행된다. 우선 정답 문장 시작 임베딩 \(\mathbf{S}\)와 정답 문장 끝 임베딩 \(\mathbf{E}\)를 정의하고 이를 문장의 \(i\)번째 토큰 \(w_i\)의 표현 벡터 \(\mathbf{T}_i\)와 내적 및 Softmax 연산을 통해서 아래와 같이 계산한다:
\[P_i = \frac{\exp(\mathbf{S} \cdot \mathbf{T}_i)}{\sum_j exp(\mathbf{S} \cdot \mathbf{T}_j)}.\]이 확률 \(P_i\)는 문장의 \(i\)번째 토큰이 정답 문장의 시작 토큰일 확률을 의미한다. 마찬가지 방법으로 문장 끝 임베딩 \(\mathbf{E}\)를 활용하여 \(i\)번째 토큰이 정답 문장의 끝 토큰일 확률도 계산한다.
<Top Learderboard Systems (Dec 10th, 2018)>
| System | Dev | Test | ||
|---|---|---|---|---|
| EM | F1 | EM | F1 | |
| Human | - | - | 82.3 | 91.2 |
| #1 Ensemble-nlnet | - | - | 86.0 | 91.7 |
| #2 Ensemble-QANet | - | - | 84.5 | 90.5 |
<Published>
| System | Dev | Test | ||
|---|---|---|---|---|
| EM | F1 | EM | F1 | |
| BiDAF+ELMo (Single) | - | 85.6 | - | 85.8 |
| R.M. Reader (Ensemble) | 81.2 | 87.9 | 82.3 | 88.5 |
<BERT>
| System | Dev | Test | ||
|---|---|---|---|---|
| EM | F1 | EM | F1 | |
| BERT BASE (Single) | 80.8 | 88.5 | - | - |
| BERT LARGE (Single) | 84.1 | 90.9 | - | - |
| BERT LARGE (Ensemble) | 85.8 | 91.8 | - | - |
| BERT LARGE (Single+TriviaQA) | 84.2 | 91.1 | 85.1 | 91.8 |
| BERT LARGE (Ensemble+TriviaQA) | 86.2 | 92.2 | 87.4 | 93.2 |
위 표는 SQuAD 1.1 버전에서의 BERT와 기존 SOTA 모델들의 성능 평가 비교이다. 현재 리더보드 상에서의 모델은 Test 셋에서의 결과만 확인 가능하고 모델 자체에 접근은 되지 않는 상황이라 Test 셋에서의 성능만을 기입하여 놓았다. BERT 역시 Test 셋에서의 성능 평가를 위해서 TriviaQA에 대해 파인 튜닝을 수행하고 평가를 진행하였다고 한다. 이 결과는 기존 모델들에 비해서 확실히 좋은 성능을 보인다.
<Top Learderboard Systems (Dec 10th, 2018)>
| System | Dev | Test | ||
|---|---|---|---|---|
| EM | F1 | EM | F1 | |
| Human | 86.3 | 89.0 | 86.9 | 89.5 |
| #1 Single - MIR-MRC (F-Net) | - | - | 74.8 | 78.0 |
| #2 Single - nlnet | - | - | 74.2 | 77.1 |
<Published>
| System | Dev | Test | ||
|---|---|---|---|---|
| EM | F1 | EM | F1 | |
| unet (Ensemble) | - | - | 71.4 | 74.9 |
| SLQA (Single) | - | - | 71.4 | 74.4 |
<BERT>
| System | Dev | Test | ||
|---|---|---|---|---|
| EM | F1 | EM | F1 | |
| BERT LARGE (Single) | 78.7 | 81.9 | 80.0 | 83.1 |
위 표는 SQuAD 2.0 버전에서의 BERT와 기존 SOTA 모델들의 성능 평가 비교이다. 1.1 버전과 마찬가지 방법으로 BERT에 대한 평가가 진행되었으며 Test 셋에서 기존 모델들에 비해서 높은 성능을 보인다.
SWAG
SWAG(Situation With Adversarial Generation) 데이터셋은 자연어 추론 태스크를 위한 데이터셋이다. 총 11만 3천 개의 문장 쌍으로 구성되어 있으며 일반 상식 수준의 자연어 추론 태스크를 담고 있다. SWAG 태스크는 주어진 문장에 대해서 가장 그럴듯한 다음 문장을 4개의 선택지에서 찾아내는 태스크이다.
SWAG 데이터셋을 통해 파인 튜닝은 다음과 같이 진행되었다. 우선 주어진 문장을 A 문장으로 설정하고, 가능한 선택 문장 4개를 각각 B 문장으로 설정하여 이어 붙인다. 이렇게 붙인 문장 쌍은 총 4개가 될 것이다. SWAG 태스크 특화된 파라미터는 문장 쌍의 [CLS] 토큰과의 내적을 통해서 각각의 선택지 문장에 대한 점수를 구할 수 있는 벡터가 있다.
| System | Dev | Test |
|---|---|---|
| ESIM+GloVe | 51.9 | 52.7 |
| ESIM+ELMo | 59.1 | 59.2 |
| OpenAI GPT | - | 78.0 |
| BERT BASE | 81.6 | - |
| BERT LARGE | 86.6 | 86.3 |
| Human (expert) | - | 85.0 |
| Human (5 annotations) | - | 88.0 |
위 표는 BERT의 SWAG 태스크에 대한 평가 결과이다. BERT LARGE는 기존 모델들의 성능을 압도하며 사람 전문가보다도 좋은 성능을 보인다.
Ablation Study
Ablation Study는 다양한 관점에서 진행되었다. 우선 사전 훈련 태스크의 효과가 어떤 것인지에 대해서 확인하였다. 아래 표는 사전 훈련 태스크에서 다음 문장 예측이 없는 경우(No NSP)와 정방향(Left-to-Right, LTR)만을 고려하면서 다음 문장 예측이 없는 경우(LTR & No NSP), 그리고 LTR & No NSP에 랜덤하게 초기화된 BiLSTM을 추가로 붙인 경우(+BiLSTM)에 대해서 성능 평가를 진행하였다.
| Task | MNLI-m (Acc) | QNLI (Acc) | MRPC (Acc) | SST-2 (Acc) | SQuAD (Acc) |
|---|---|---|---|---|---|
| BERT BASE | 84.4 | 88.4 | 86.7 | 92.7 | 88.5 |
| No NSP | 83.9 | 84.9 | 86.5 | 92.6 | 87.9 |
| LTR & No NSP | 82.1 | 84.3 | 77.5 | 92.1 | 77.8 |
| + BiLSTM | 82.1 | 84.1 | 75.7 | 91.6 | 84.9 |
위의 모든 태스크는 각 데이터셋의 Dev Set에 대해서 수행되었다. 우선 다음 문장 예측이 어떤 영향을 주는지에 대한 실험에서는 BERT BASE에 비해서 확실하게 성능 저하가 나타나는 것을 확인할 수 있었다. 여기에 추가로 양방향성을 제거하고 오직 정방향만을 고려하도록 하는 경우 성능이 훨씬 더 많이 감소했다.
정방향 모델의 성능을 강화하기 위하여 BiLSTM을 추가하여 진행한 실험에서는 SQuAD 태스크에 대해서는 성능 향상을 확인할 수 있었지만 다른 태스크들에서는 여전히 낮은 성능만을 확인할 수 있었다.
그 다음으로 진행한 Ablation Study는 모델 사이즈에 대한 실험이다. 모델 사이즈가 실제로 모델의 성능에 어떤 영향을 주는지에 대한 확인 실험이라고 보면 된다. 아래 표는 몇 가지 GLEU 태스크에 대한 모델 사이즈에 따른 성능 평가 실험 결과를 나타내는 표이다. 해당 실험은 Dev Set에 대해서 진행되었다.
| #L | #H | #A | LM (ppl) | MNLI-m | MRPC | SST-2 |
|---|---|---|---|---|---|---|
| 3 | 768 | 12 | 5.84 | 77.9 | 79.8 | 88.4 |
| 6 | 768 | 3 | 5.24 | 80.6 | 82.2 | 90.7 |
| 6 | 768 | 12 | 4.68 | 81.9 | 84.8 | 91.3 |
| 12 | 768 | 12 | 3.99 | 84.4 | 86.7 | 92.9 |
| 12 | 1024 | 16 | 3.54 | 85.7 | 86.9 | 93.3 |
| 24 | 1024 | 16 | 3.23 | 86.6 | 87.8 | 93.7 |
위 결과를 통해 우리는 사이즈가 더 큰 모델이 확실히 높은 성능을 보이는 것을 확인할 수 있다. 또한 추가로 주목해야할 사항은 다음과 같다. 지금까지 거대한 태스크에 대해서는 거대한 모델이 높은 성능을 보인다는 것은 잘 알려져있는 사실이었다. 하지만 저자들은 이 실험을 통해서 작은 태스크에 대해서도 거대한 모델이 더 높은 성능을 보일 수 있다는 것을 확인할 수 있다고 한다. 물론 해당 모델은 사전 훈련이 충분히 진행된 이후이다.
다만 작은 태스크에 대한 결과는 이전 연구들에서는 사이즈를 증가시키면 오히려 성능이 감소하는 결과를 확인할 수 있었다. 이 이전 연구들의 공통점은 특징 기반 접근(Feature-based Approach)를 사용했다는 점이다. 특징 기반 접근은 파인 튜닝 기반 접근과는 다르게 사전 훈련된 모델이 아닌 입력 특징을 활용하여 태스크를 수행하는 모델을 말한다.
즉, 이 실험을 통해서 저자들은 모델이 하위 태스크들에 대해서 직접 파인 튜닝이 수행되고 오직 적은 수량의 랜덤하게 초기화된 파라미터가 활용된다면 매우 강력한 표현력을 가지면서 하위 태스크의 사이즈가 매우 작더라도 태스크 특화된 모델이 매우 강력한 성능을 보일 수 있다고 추론하고 있다.
마지막으로 진행한 Ablation Study는 특징 기반 접근에 대한 실험이다. 위에서 잠깐 설명하였듯이 특징 기반 접근은 사전 훈련 + 파인 튜닝 방식이 아닌 입력 특징을 직접 태스크에 활용하는 모델링 접근 방식이다. 이 실험을 위해서 BERT의 특징 기반 접근은 사전 훈련된 BERT 모델의 고정된 중간 특징들을 추출하여 활용하였다.
<Published>
| System | Dev F1 | Test F1 |
|---|---|---|
| ELMo | 95.7 | 92.2 |
| CVT | - | 92.6 |
| CSE | - | 93.1 |
<Fine-Tunning Approach>
| System | Dev F1 | Test F1 |
|---|---|---|
| BERT LARGE | 96.6 | 92.8 |
| BERT BASE | 96.4 | 92.4 |
<Feature-based Approach Approach>
| System | Dev F1 | Test F1 |
|---|---|---|
| Embeddings | 91.0 | - |
| Second-to-Last Hidden | 95.6 | - |
| Last Hidden | 94.9 | - |
| Weighted Sum Last Hidden | 95.9 | - |
| Concat Last Four Hidden | 96.1 | - |
| Weighted Sum All 12 Layers | 95.5 | - |
위 표는 특징 기반 접근에 대한 Ablation Study 실험 결과를 정리한 것이다. BERT LARGE는 기존 SOTA 모델들에 비해서 충분히 경쟁적인 성능을 보인다. 위 결과에서 확인할 수 있듯이 BERT 모델은 특징 기반 접근을 통해서도 파인 튜닝 기반 접근과 성능 차이가 크게 나지 않는다.
정리
BERT는 Transformer 구조를 활용하여 자연어 토큰에 대한 표현 벡터를 생성하는 인코더 학습 과정에서 인코더 스스로가 자연어를 어느정도 이해하여 인코딩을 수행할 수 있도록 학습이 가능하다는 것을 보여줬다. 이를 통해서 라벨링이 되어있지 않은 거대한 말뭉치를 통해서 사전 훈련이 가능하였고 여기에 태스크 특화된 일부 라벨링 데이터만으로도 SOTA 이상의 성능을 얻을 수 있음을 보였다. BERT의 이러한 성과 덕분에 앞으로의 자연어 처리 연구는 거대한 라벨링 비용을 절감할 수 있게 되었다.
또한 저자들은 자신들의 연구 성과로 진정한 의미의 심층 양방향 모델을 제안했다는 점을 들고 있다. 이러한 진정한 의미의 양방향성은 BERT로 하여금 자연어 이해도를 훨씬 높일 수 있었고 결과적으로 대부분의 NLP 태스크에서 우수한 성과를 보일 수 있도록 하였다고 주장한다.
참고 자료
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- Deep contextualized word representations
- Improving Language Understanding by Generative Pre-Training
수정 사항
- 2024.01.02
- 최초 게제