새로운 업무를 위하여 자연어 처리 스터디를 진행하였고 해당 내용에 대해서 연재를 해보려고 한다. 자연어 처리의 기초부터 BERT, GPT 등의 인공 신경망 기반의 언어 모델, 그리고 더 나아가 최근 매우 큰 관심을 받고 있는 ChatGPT까지 다뤄보는 것을 목표로 한다.
목차
자연어 처리란?
기계의 자연어 처리(Natural Language Processing)란 기계가 이해할 수 없는 형태, 즉 비정형 데이터의 형태를 갖는 자연어를 기계가 이해할 수 있는 형태로 변환하고 또 더 나아가 이를 통해 파생되는 다양한 태스크들을 수행하는 인공지능의 한 분야를 말한다.
일단 이 말을 이해하기 위해서 정형 데이터와 비정형 데이터의 의미를 먼저 확인하도록 하자. 정형 데이터란 데이터를 표현하기 위한 적절한 스키마(Schema)가 미리 정의되어 있는 데이터를 말한다. 좀 더 쉽게 설명하면 관계형 데이터베이스나 스프레드시트처럼 데이터를 표현하는 하나의 행(Row)에 대해서 이 데이터는 스키마가 이미 결정되어 있다는 것을 확인할 수 있겠다. 반면 비정형 데이터는 정형 데이터가 아닌 모든 데이터의 형태, 즉 스키마가 정의되어 있지 않은 데이터를 말한다. 비정형 데이터의 대표적인 예시로는 영상(Image) 데이터를 들 수 있다.
자연어 데이터는 대표적인 비정형 데이터이다. 자연어 데이터는 각각의 심벌(Symbol)이 유니코드 상에서 어떤 특정 문자(Character)를 나타낼 뿐 어떠한 스키마가 결정되어 있지 않다. 스키마가 결정되어 있지 않다는 의미는 결국 기계가 이를 즉각적으로 이해할 수 없다는 의미가 된다. 물론 스키마가 존재하고 있다고 해서 기계가 그 데이터의 의미론적(Semantic)으로 이해하고 있다고 볼 수는 없지만, 그 데이터를 어쨌거나 다양한 방식으로 다룰 수 있게 된다. 이에 대한 대표적인 증거로 바로 SQL과 같은 쿼리(Query)문을 이용해 필요한 데이터를 뽑아내거나 수정할 수 있는 점을 들 수 있겠다.
좌우지간 우리는 향후 스터디를 통해서 기계가 자연어를 이해할 수 있도록 돕는(물론 이것을 자연어를 이해하고 있다고 말할 수 있을지는 여전히 논란의 여지가 있다.) 많은 방법론들을 다뤄볼 수 있을 것이다.
단어 임베딩
자연어 처리 방법론을 적용하기 위해서는 기본적으로 지연어에 대한 토큰화(Tokenization)과정을 거친다. 토큰화란 자연어 문장을 어떤 특정 단위로 자르는 행위를 말한다. 영어 문장에 대한 대표적인 토큰화 과정은 단어(Word) 단위로 나누는 것이다. 만약 “I Love You”라는 문장이 있다면 이 문장을 단어 단위로 토큰화한 결과는 (“I”, “Love”, “You”)의 형태가 될 것이다. 한국어 문장에 대해서는 “은/는/이/가”에 해당하는 조사의 존재로 인하여 단어 단위의 토큰화는 사실상 불가능하다. 대신 한국어는 형태소 분석이라는 방법을 통해서 토큰화를 수행한다.
토큰화 이후 기계 학습에 이 토큰화 결과를 활용하기 위해서는 기계 학습 모델의 입력으로 활용되기 위한 특징화(Featurization) 과정이 필요하다. 자연어 처리가 대표적으로 활용되던 분야는 이메일에서 스팸 메일을 구분하는 태스크였다. 이 태스크를 위하여 메일 한 통에 해당하는 자연어 말뭉치, 즉 문장들의 집합을 특징화할 필요가 있었다. 여기에는 Bag of Words라는 이름의 특징(Feature)을 활용하였다. Bag of Words는 말 그대로 단어들의 가방을 의미하며 가방안에 단어들을 모두 집어넣고 이를 통째로 특징으로 활용하겠다는 의도가 담겨 있었다.
Bag of Words는 토큰화 과정을 거쳐서 나온 모든 단어들의 목록과 그 단어들의 등장 빈도를 정보로 담고 있다. 이 정보들을 바탕으로 스팸 메일을 구분하는 것이 이전 자연어 처리의 중요한 방법이었다. 여기서 사용된 아이디어는 스팸 메일은 특정 단어들을 많이 포함하고 있다는 가정을 바탕으로 나온 것이다. 이는 꽤나 괜찮은 성과를 보였었던 것으로 보인다.
여기서 우리는 Bag of Words가 치명적인 문제점을 안고 있다는 것을 확인할 수 있다. 일단 단어들의 빈도수만을 가지고 그 문장, 또는 말뭉치의 특징을 모두 추출했다고 단정지을 수 없다는 사실은 우리 모두가 알 것이다. 같은 단어의 빈도수를 가지고 있더라도 그 단어들의 조합 방법에 따라서 그 문장 또는 말뭉치가 다르게 해석될 수 있다. 따라서 언어의 특징을 활용하기 위해서는 단순 빈도수 뿐 아니라 조합 방법에 대해서도 고민을 해봐야 한다는 결론을 내릴 수 있다.
인공 신경망이 등장하면서 인공 신경망을 통한 자연어 특징화에 대해서도 많은 시도들이 수행되어 왔다. 가장 대표적이고 중요한 연구 성과는 단어 임베딩(Word Embedding)을 들 수 있다. 임베딩이란 인공 신경망을 통한 특징화 방법론 중 하나인데 특정 특징들을 우리가 원하는 형태 또는 성질의 벡터 공간으로 투영(Projection)하는 것을 말한다. 말이 좀 어려운데 단어 임베딩이란 결국 토큰화 결과에 해당하는 각각의 토큰, 즉 단어들에 대해서 벡터화를 수행하는데 이 벡터들이 놓여있는 벡터 공간은 우리가 원하는 어떤 특징을 보유하게 될 것이라는 의미이다.
그러면 이러한 공간은 어떤 특징을 갖고 있어야 할까? 이를 위한 가장 대표적인 연구 성과는 Word2Vec이다. Word2Vec은 단어 임베딩을 통한 토큰 특징화 접근의 대표적인 방법이다. Word2Vec은 Distributional Hypothesis라는 가정을 바탕으로 진행되는데 이 가정의 가장 핵심은 유사한 의미의 단어들은 말뭉치 내의 가까운 위치상에서 등장할 확률이 높다는 것이다. 이 가정을 바탕으로 Word2Vec에서는 벡터 공간의 구성을 가까운 곳에서 등장하는 단어들은 벡터 공간상에서도 가깝도록 설정하려고 시도했다.
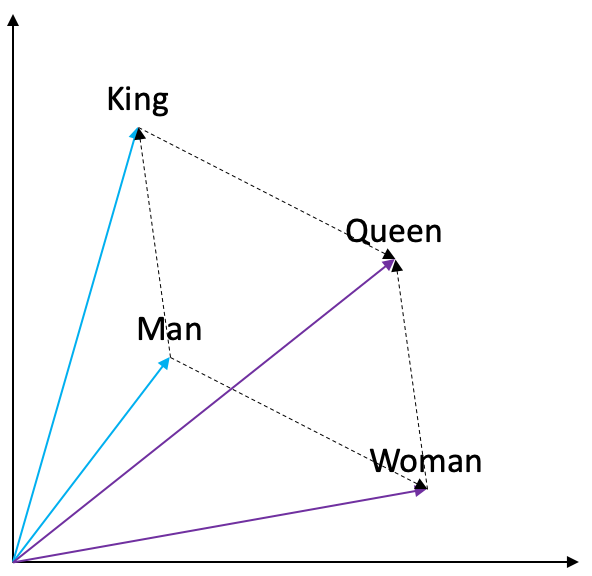
위의 사진은 단어 임베딩이 아주 잘 학습되었을 경우에 확인할 수 있는 대표적인 예시이다. “Man”이라는 단어와 “King”이라는 단어 사이의 관계는 “Woman”이라는 단어와 “Queen”이라는 단어 사이의 관계와 동일하며 이는 또 다른 표현으로 “Man”과 “Woman”의 관계와 “King”과 “Queen”의 관계가 동일하다는 표현으로 다시 쓰여질 수 있다. 이러한 관계들 사이의 특징들은 단어 임베딩 공간 상에서 선형적인 관계로 잘 표현되게 된다. 이러한 현상을 Word Embedding Analoygies라고 한다.
어쨌든 이렇게 잘 훈련된 단어 임베딩 벡터는 단어 사전에 대한 테이블로 존재하며 특정 단어를 그 단어에 해당하는 임베딩 벡터로 매핑하여 활용하게 된다. 이렇게 변환된 임베딩 벡터는 인공 신경망 모델의 입력으로 사용될 수 있고 향후 다양한 태스크들에 적절히 활용되게 된다.
언어 모델
언어 모델(Language Model)이란 주어진 특정 단어(또는 토큰) 순서의 등장 확률에 대한 모델이다. 다시말하면 주어진 단어들의 나열에 대해서 이 나열이 얼마나 자연스러운지에 대한 점수를 나타낼 수 있는 모델을 언어 모델이라고 할 수 있겠다. 언어 모델은 기본적으로 아래와 같은 주어진 단여들의 나열에 대한 결합 확률 분포(Joint Probability Distribution)로 표현된다:
하지만 최근에는 문맥(Context)을 고려한 언어 모델의 표현 방식을 더 선호한다고 알려져있다. 즉 다음과 같은 형태의 언어 모델을 더욱 선호한다:
즉 주어진 문맥에 대해서 특정 단어가 등장할 확률을 언어 모델로 정의한다. 이러한 방식으로 훈련되는 언어 모델로 대표적인 것으로 Skip-Gram 모델과 최근에 각광받고 있는 BERT를 들 수 있다.
통계적 언어 모델
통계적 언어 모델(Statistical Language Model)은 위에서 언급했던 것처럼 특정 단어 순서의 등장 확률에 대한 모델이다. 통계적이라는 말에서 알 수 있듯 기본적으로 주어진 단어의 빈도수에 비례하는 확률 모델을 따른다. 가장 단순한 통계적 언어 모델은 유니그램 언어 모델(Unigram Language Model)이다. 유니그램 언어 모델은 주어진 단어의 나열에 대해서 각각의 단어가 서로 독립이라는 가정을 가지고 있다. 즉 다음과 같이 쓰게 된다:
유니그램 언어 모델은 단어의 순수한 등장 빈도를 통해서 언어 모델링을 수행한다는 측면에서 간단하지만 위에서 언급했던 문맥을 고려하지 못한다는 점이 그 단점이다. 문맥을 고려할 수 있는 가장 단순한 통계적 언어 모델로 바이그램 언어 모델(Bigram Language Model)을 들 수 있다. 바이그램 언어 모델은 하나의 단어를 문맥으로 삼고 그 다음에 등장할 단어의 분포를 고려한다. 즉 다음과 같다:
마찬가지로 트라이그램 언어 모델(Trigram Language Model)은 다음과 같이 정의할 수 있다:
이를 특정 \(N\)에 대해 일반적으로 작성할 수 있다. 이를 N-gram 언어 모델(N-gram Language Model)이라고 정의한다:
Skip-Gram 모델
Skip-Gram 모델은 Word2Vec을 위한 초창기 모델이다. 기본적으로 특정 범위의 윈도우(Window) 내부에서 특정 위치의 단어가 어떤 단어가 나올지에 대한 분류 모델의 형태를 지니고 있다. 아래는 Skip-Gram 모델이 어떤 방식으로 언어 모델링을 수행하는지에 대한 그림이다.

여기서는 “Success is walking from failure to failure with no loss of enthusiasm.”이라는 문장에 대한 언어 모델링 예시를 보여준다. 일단 빨간 박스는 Skip-Gram 모델의 윈도우 크기를 말한다. 여기서는 5로 설정되어 있다. Skip-Gram 모델은 윈도우 내부에서 가운데에 올 단어가 어떤 단어인지를 분류하는 방식으로 훈련이 진행된다. 즉 주어진 윈도우의 위치가 문맥이고 이렇게 주어진 문맥에 대해서 가운데에 올 단어가 어떤 단어인지를 분류하는 것이다.
첫 번째 행에서의 문맥은 (“Success”, “is”, “from”, “failure”)이고 이 문맥을 통해서 가장 가운데에 있는 단어인 “Walking”을 잘 분류해내는 것이 이 모델에 주어진 태스크이다. Skip-Gram 모델은 다음 포스트에서 더욱 자세히 다뤄보도록 하겠다.
마스크 언어 모델
마스크 언어 모델(Masked Language Model, MLM)은 주어진 훈련용 문장에 대해서 중간중간에 빈 칸을 만들어 놓고 이 빈 칸에 들어올 적절한 단어를 분류하는 과정으로 학습되는 언어 모델을 말한다. 여기서는 주어진 문맥이 있으면 이 문맥을 바탕으로 빈 칸에 들어올 적절한 단어를 추론할 수 있는 언어 모델이 학습될 것이다. 대표적인 MLM으로는 BERT를 들 수 있다.
마스크 언어 모델이 유의미한 이유는 빈 칸에 들어갈 단어를 맞추는 태스크를 수행하면서 자연스럽게 언어의 특징을 이해하는 훈련이 될 수 있다는 점이다. 실제로 이렇게 사전 훈련(Pretrained)이 된 마스크 언어 모델은 마치 언어의 특징을 이해하는 것처럼 훌륭한 단어(토큰) 또는 문장의 표현 방식을 추출해낼 수 있다는 것이 증명되고 있다.
자연어 처리의 다양한 태스크
자연어 처리에는 크게 문서 분류, 개체명 인식, 질의 응답, 문장 생성, 기계 번역 등의 다양한 태스크들이 존재한다. 각 태스크들에 대해서 간단히 알아보도록 하자.
문서 분류
문서 분류(Document Classification)이란 주어진 문서에 대해서 문서가 속한 카테고리를 분류해내는 태스크이다. 일반적으로 단어 임베딩을 활용한 문서 임베딩 과정을 통해서 문서 분류 태스크가 수행되게 되는데 여기서 문서 임베딩은 문서에 속한 단어들의 임베딩을 통해서 수행되게 된다.
초기 문서 분류 모델은 주어진 문서의 모든 단어(토큰)들에 대해 Bag of Words를 구성하고 이 표현(Representation)을 통해서 분류를 하는 모델을 기본으로 하여 연구가 진행이 되어왔다. 이를 위하여 선형 회귀, 또는 선형 분류 모델이 활용되어 왔었고 여기에 더해서 Support Vector Machine(SVM)이 활용되기도 했었다. 최근에는 Word2Vec을 기본적으로 활용하고자 하며 주어진 문서가 포함하는 모든 단어들의 임베딩 벡터의 중간 벡터를 활용하는 방식으로 문서 임베딩을 수행한다.
물론 이런 방식의 활용은 단순 등장 단어들의 평균적인 표현 방식이기에 좋은 표현이라고 생각하기 힘들다. 따라서 문서 분류를 위한 태스크에 맞는 새로운 인공 신경망 계층(Layer)을 구성하여 활용하기도 한다. 예를 들면 RNN을 활용하여 문서에 등장하는 모든 단어 임베딩의 나열을 특정 표현으로 인코딩(Encoding)을 수행하고 이 표현을 바탕으로 다시 인공 신경망을 거쳐 문서 분류를 수행하는 방식을 들 수 있다. 여기서 중간에 인코딩된 표현이 바로 (주어진 문서 분류 태스크에 특화된) 문서 임베딩이 될 것이다.
개체명 인식
개체명 인식(Named Entity Recognition)이란 주어진 문장에서 각각의 단어(또는 토큰)에 대해 해당 토큰이 인명, 지명, 조직 등 어떤 것을 의미하는 것인지를 분류하여 태깅하는 태스크를 말한다. 아래의 문장을 통해서 예를 한 번 들어보자.
노형철은 2023년에 이노뎁에 입사했다.
여기서 “노형철”은 인명(Person), “2023년”은 시간(Time), “이노뎁”은 조직(Organization)을 의미하는 개체명으로 인식될 수 있다.
일반적으로 개체명 인식 태스크의 경우 각 토큰별로 해당 토큰이 어떤 개체명 범주로 분류될 수 있는지에 대한 범주(Category) 리스트가 사전에 미리 정의되어 있어야 한다. 위의 예시를 바탕으로 하면 분류 범주였던 인명, 시간, 조직 등의 범주가 미리 정의되어 있어야만 할 것이다.
질의 응답
질의 응답(Question Answering)은 주어진 질문에 대해서 적절한 답변을 수행하는 자연어 처리의 태스크이다. 기본적으로 문맥이 되는 자연어 정보가 주어지고 이 문맥을 바탕으로 주어지는 질문에 대해서 답변을 수행하는 방식으로 구성되어 있는 태스크이다. 주어지는 질문의 특징에 따라서 질의 응답 태스크는 Single-Turn과 Multi-Turn으로 나뉠 수 있다.
Single-Turn의 경우 단편적인 한 번의 질문에 대한 적절한 답변을 내놓는 것을 목표로 한다. 이 말의 정확한 의미를 이해하기 위해서는 Multi-Turn과 어떤 차이가 있는지를 살펴보는 것이 더 빠를 수 있다. 가령 다음과 같은 질문이 들어왔다고 해보자.
오늘 날씨가 어때?
여기에 대해서 “오늘 날씨는 맑습니다.” 라고 답변을 했다고 가정해보자. 여기에 대해서 바로 다음과 같은 질문이 또 들어온다고 해보자.
내일은?
여기에 대해서 Multi-Turn 질의 응답의 경우는 이를 제대로 답변하는 것을 목표로 하고 Single-Turn의 경우는 그렇지 않다. 최근에 각광받고 있는 다양한 챗봇들은 모두 이러한 Multi-Turn 질의 응답이 가능하도록 개발을 진행하고 있고 이는 자연어 처리에서 매우 중요한 분야 중 하나로 현재 연구되고 있다.
문장 생성
문장 생성(Sentence Generation)이란 주어진 문맥에 대해서 다음 문장을 생성하는 태스크를 말한다. 좀 더 구체적으로는 주어진 문맥에 대해서 바로 다음에 나올 단어가 어떤 단어일지 분류하는 방식으로 훈련이 진행되고 이렇게 훈련된 모델은 다음에 나올 단어를 한 단계씩 골라가며 문장을 생성할 수 있게 된다. 이는 기본적으로 언어 모델을 훈련하는 방식과 동일하며 적절한 언어 모델을 통해서 문장 생성이 가능하도록 할 수 있다.
최근 인공지능 분야에서 각광받고 있는 Chat-GPT의 경우도 이러한 문장 생성 태스크에 특화된 생성형 언어 모델이다. Chat-GPT는 주어진 문장에 대해서 답변으로 가장 그럴듯한 문장을 생성하는 태스크를 수행하는 문장 생성 모델이다.
기계 번역
기계 번역(Machine Translation)은 말 그대로 주어진 문장을 다른 언어로 번역하는 태스크를 말한다. 기본적으로 기계 번역은 인코더(Encoder)와 디코더(Decoder)로 이루어진 Sequence-to-Sequence(seq2seq) 모델을 통해서 수행된다. 아래의 그림은 RNN 기반의 seq2seq 모델을 통한 기계 번역이 이루어지는 방식을 간단히 설명하고 있다.
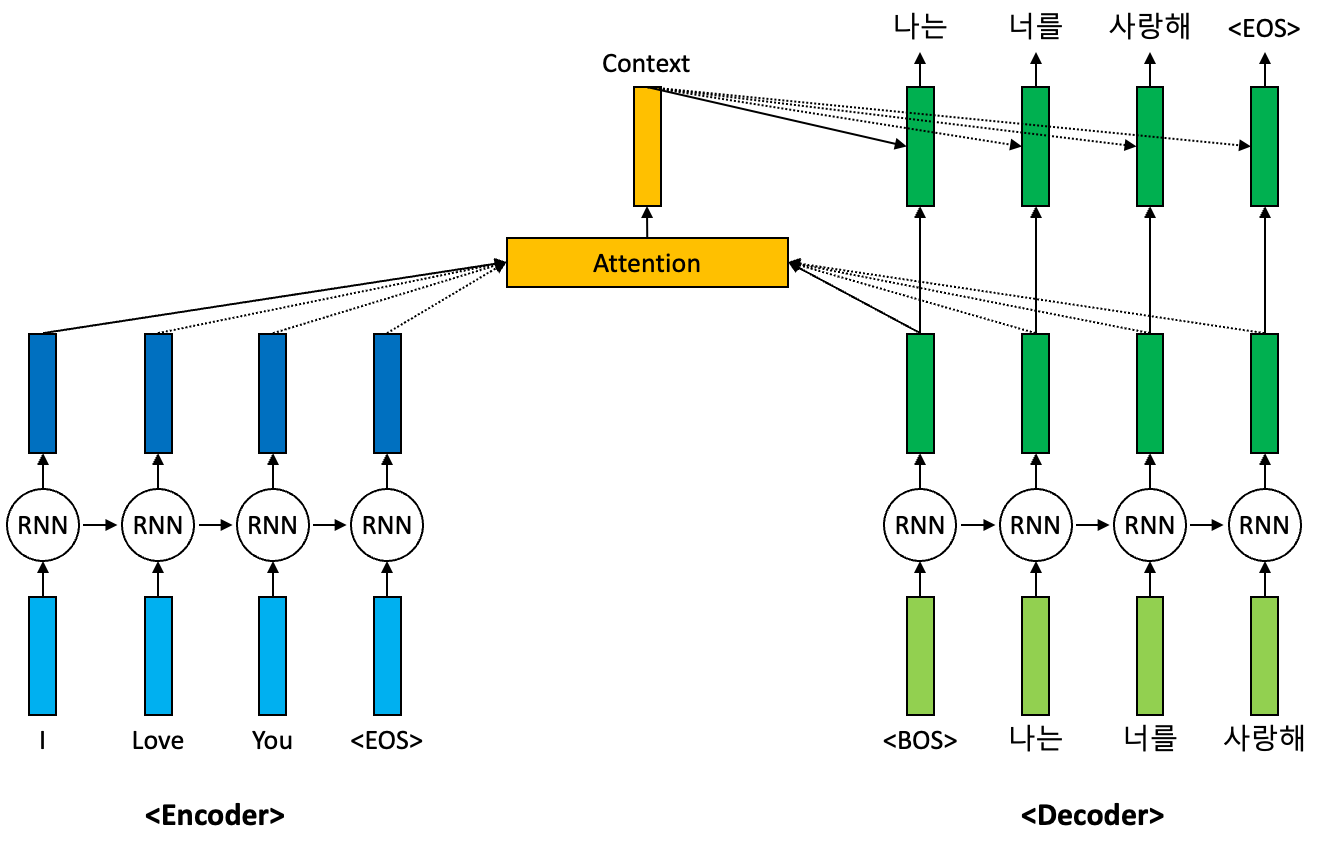
위 그림을 간단히 설명해보자. 먼저 위 그림은 “I love you”라는 문장을 “나는 너를 사랑해”라는 문장으로 번역하는 과정을 말한다. 입력 문장은 먼저 인코더를 통과하여 각 토큰별로 인코딩이 수행되게 된다. 이렇게 입력 문장에 대한 인코딩이 진행이 되고 나서 디코더를 통해서 입력 문장에 대한 번역 결과를 순차적으로 생성하게 된다. 먼저 디코더에는 문장의 시작을 의미하는 토큰 “<BOS>“가 입력된다. BOS는 Begin of Sentence라는 의미이다.
그 다음으로 디코더는 “<BOS>” 토큰을 적절한 표현으로 변환하고 이 표현과 인코더를 통해서 생성된 입력 문장의 각 토큰별 표현들 사이에서 Attention 메커니즘이 수행된다. Attention 메커니즘은 현재 생성하고자 하는 토큰을 위해서 활용하는 입력 문장 토큰들에 대한 표현들 중 어떤 표현들에 얼마만큼의 가중치를 줄 것인지를 계산해주는 역할을 가지고 있다. 이렇게 구한 가중치를 통해서 입력 문장 토큰들에 대한 표현들에 대한 가중 평균을 계산하고 이는 현재 문맥을 담고있다는 의미로 문맥 벡터(Context Vector)라고 명명한다. 이렇게 생성된 문맥 벡터는 현재 토큰의 생성에 참여하여 적절한 토큰을 생성한다.
최근의 기계 번역은 RNN 기반이 아닌 Transformer 기반의 모델을 통해서 수행되고 있다. 이에 대한 자세한 설명은 추후에 또 다뤄보도록 하겠다.
참고 자료
수정 사항
- 2023.02.17
- 최초 게제
- 2023.02.23
- 이미지 크기 조절
- 2023.02.24
- 통계적 언어 모델 내용 추가
- 2023.11.19
- 자료 보강 및 목차 추가