Please check my github: https://github.com/hcnoh/multi-speaker-tacotron-tensorflow
Multi-Speaker Tacotron Implementation in TensorFlow
Multi-Speaker 기능을 가진 Tacotron 모델의 TensorFlow 구현입니다. 이 저장소는 Baidu의 Deep Voice 2 논문을 기반으로 구현하였습니다. Multi-Speaker 기능은 선택적으로 사용, 또는 사용하지 않을 수 있으며 만약 Multi-Speaker 기능을 사용하지 않는다면 기존의 Tacotron 모델과 동일합니다.
Installing Dependencies
- 파이썬 3.5 버전을 설치합니다.
- TensorFlow 1.10.0 버전 설치합니다. GPU가 사용가능하다면 GPU 버전을, 그렇지 않다면 CPU 버전을 설치합니다. 참고로 Generating을 수행하는 경우에는 CPU 버전으로도 충분합니다.
-
파이썬 패키지(Requirements)를 설치합니다. 설치는 아래와 같은 명령을 통해 수행 가능합니다.
$ pip install -r requirements.txt아래와 같이
virtualenv를 활용하여 더 쉽게 패키지 관리를 할 수도 있습니다.virtualenv가 이미 설치되어 있다는 가정 하에 아래의 명령을 수행하면 됩니다.$ virtualenv --system-site-packages -p python3 tacotron-venv $ source ./tacotron-venv/bin/activate $ pip install -r requirements.txt
Training
Note: 데이터 세트를 다운로드받기 위한 여유분의 저장 공간이 필요합니다. LJ Speech 데이터 세트를 기준으로 약 80GB 이상의 저장 공간이 필요합니다.
-
음성 데이터 세트를 다운로드합니다.
이 저장소는 다음의 데이터 세트에 대한 활용을 제공합니다.
-
데이터 세트를 원하는 위치에 Unpack합니다.
Unpacking 이후에는 디렉토리 구조가 다음과 같아야 합니다.
dataset ├── LJSpeech ├── wavs ├── LJ001-0001.wav (name doesn't matter) ├── LJ001-0002.wav └── ... ├── metadata.csv └── README ├── kss ├── 1 ├── 1_0000.wav (name doesn't matter) ├── 1_0001.wav └── ... ├── 2 ├── 3 ├── 4 ├── transcript.txt └── transcript.v.1.1.txt ├── tfrecord ├── VCTK ├── VCTK-Corpus ├── txt ├── p225 ├── p225_001.txt (name doesn't matter) ├── p226_002.txt └── ... ├── p226 └── ... ├── wav ├── p225 ├── p225_001.wav (name doesn't matter) ├── p226_002.wav └── ... ├── p226 └── ... ├── COPYING ├── NOTE ├── README └── speaker-info.txt ├── license_text └── README.txt └── ... -
hyparams.py의 스크립트에서 Training을 위한 데이터 세트 이름 및 각각의 Path들을 수정하여 줍니다.dataset_paths같은 경우는 LJ Speech와 kss의 경우LJSpeech및kss디렉토리까지 명시해줘야 하며, VCTK 같은 경우는VCTK-Corpus디렉토리까지 명시해줘야 합니다. -
데이터 세트 전처리를 수행합니다.
$ python preprocess.py -
모델 Training을 수행합니다.
$ python train.py
Generating
학습된 모델을 이용하여 음성을 생성하기 위해서는 generate.py를 실행하면 됩니다. hyparams.py의 for generating 부분을 원하는 경로로 바꿔주고 바로 실행하면 됩니다. Multi-Speaker 기능 사용 여부에 따라서 실행 방식이 달라질 것이지만 사용하는데 어려움이 없을 것입니다.
$ python generate.py
Results
106000 Steps:
-
Mel Spectrogram Sample
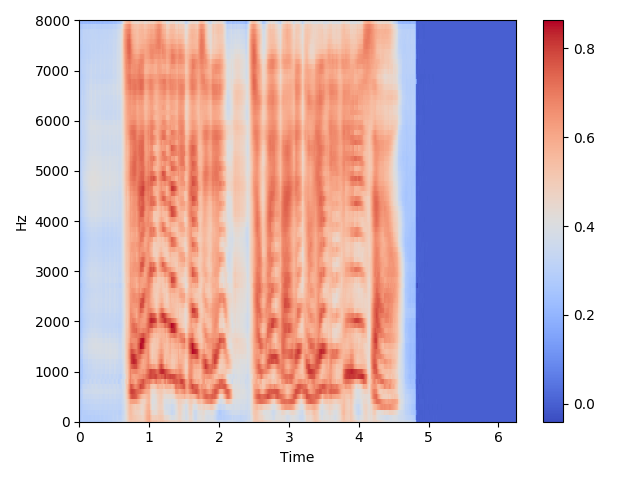
-
Linear Spectrogram Sample
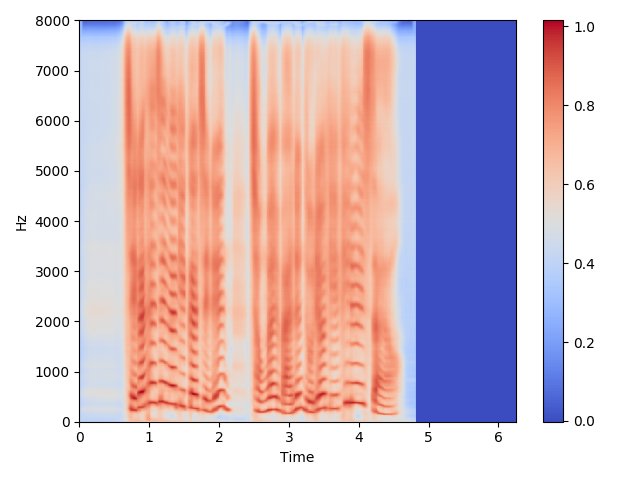
-
Attention Alignment Sample
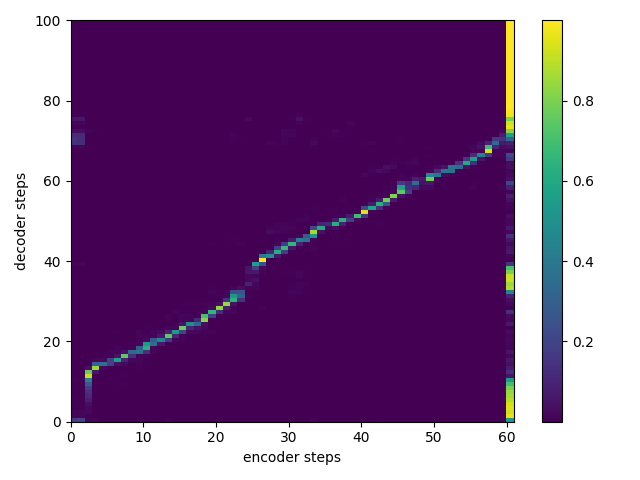
382000 Steps:
-
Mel Spectrogram Sample
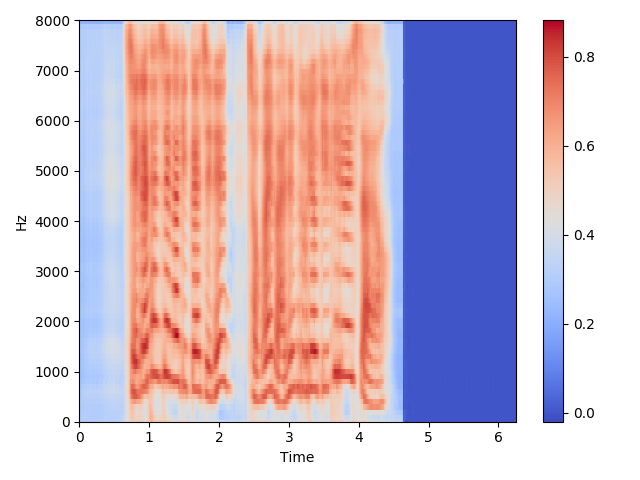
-
Linear Spectrogram Sample
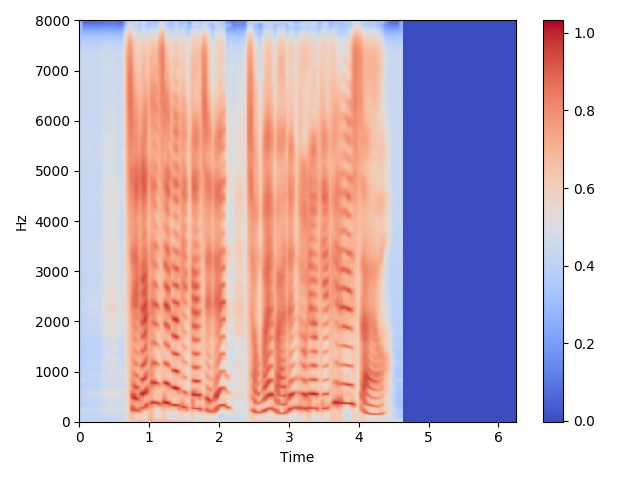
-
Attention Alignment Sample
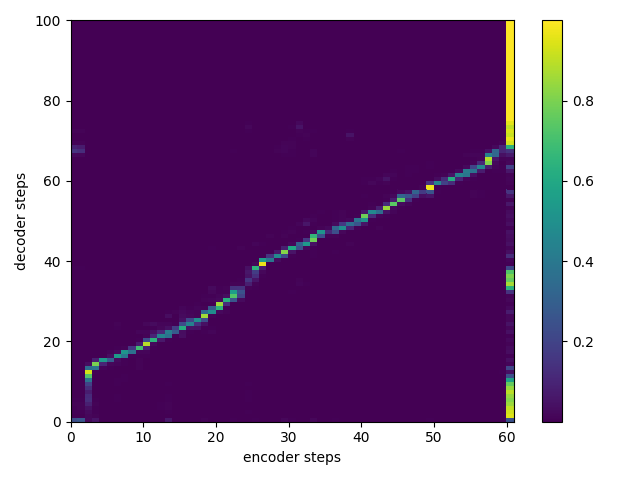
Recent Updates
- 현재 Multi-Speaker 기능 실험을 위한 여러 기능들이 구현되어 있지만 지금 당장은 사용하기 어려운 상태입니다.
- Results 작성을 완료하였습니다.
References
- Tacotron: Tacotron: Towards End-to-End Speech Synthesis
- Deep Voice 2: Deep Voice 2: Multi-Speaker Neural Text-to-Speech
- Tacotron Implementation by Keithito: https://github.com/keithito/tacotron
- Multi-Speaker Tacotron Implementation by Taehoon Kim: https://github.com/carpedm20/multi-speaker-tacotron-tensorflow